EvoMaster 是上海交通大学 SAI 团队开源的一个“科研智能体底座框架”,核心目标不是做一个固定功能的单体 Agent,而是提供一套可扩展、可复现、可持续进化的“科研工作流操作系统”。如果一句话概括:它试图把“科学研究中的试错迭代”内置成 Agent 的默认运行方式,而不是一次问答式的静态执行。
1. 为什么 EvoMaster 值得单独看?
在“AI for Science”语境里,很多项目都能做出一个能跑 demo 的 Agent,但跨学科迁移和长期迭代经常很难:工具链耦合重、配置散、实验不可复现、跑完即忘。EvoMaster 的价值在于它把这些“工程痛点”抽象成框架层能力,目标是让研究者可以用较少代码快速拼出领域 Agent,并且保留完整实验轨迹用于复盘。
论文(arXiv:2604.17406)给出的四条主张非常清晰:模块化可组合、实验就绪、迭代自进化、多智能体协同进化。框架文档中的目录结构与接口设计,基本就是这四条原则的代码化落地。
2. 总体设计:三层执行架构
EvoMaster 的执行层分为 Playground -> Exp -> Agent 三层:
Playground:工作流编排层,负责多智能体协作、并行执行、组件初始化、结果聚合。Exp:单次实验执行层,负责一次任务实例的生命周期与结果保存。Agent:智能决策层,负责多轮推理、工具调用、上下文管理与轨迹记录。
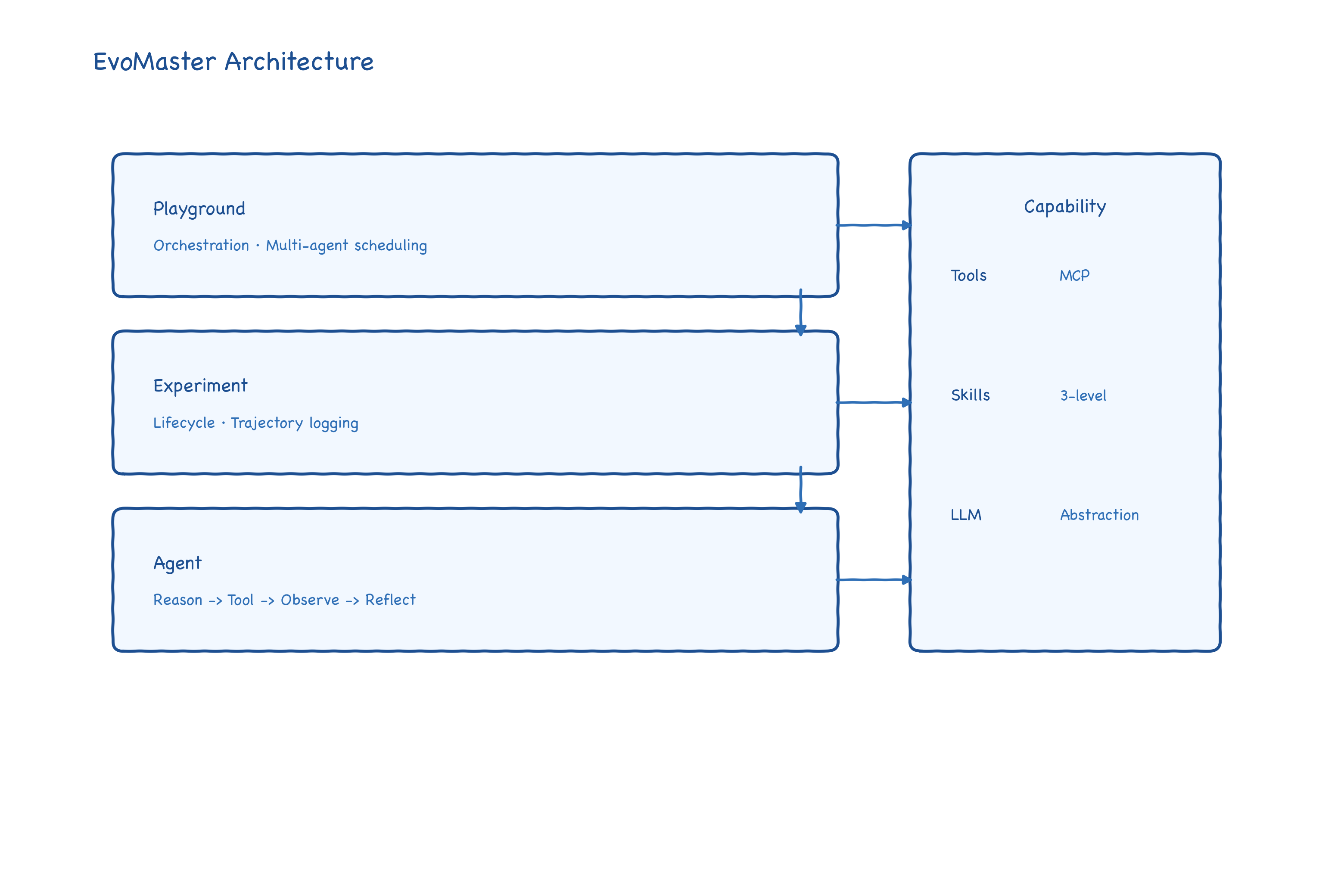
这三层拆分背后的关键收益是“横向复用”:你要切到新领域时,通常只改 Playground 逻辑和少量配置,底层 Agent 循环、工具注册、会话管理不必重写。
3. Agent 引擎:从“一次执行”变为“持续进化”
EvoMaster 的核心不是“会不会调用工具”,而是“能否在长回合里持续修正策略”。BaseAgent 负责把任务放进多轮反应式循环中:推理、调用工具、观察结果、再决策。对科研任务来说,这比单轮回答更接近真实研究过程。
在这个循环里,ContextManager 是关键基础设施。它支持上下文截断策略(如 LATEST_HALF、SLIDING_WINDOW、SUMMARY),用于在长任务中控制上下文长度,防止信息淹没与 token 爆炸。也就是说,EvoMaster 把“记忆管理”显式做成了框架能力,而非让业务代码临时打补丁。
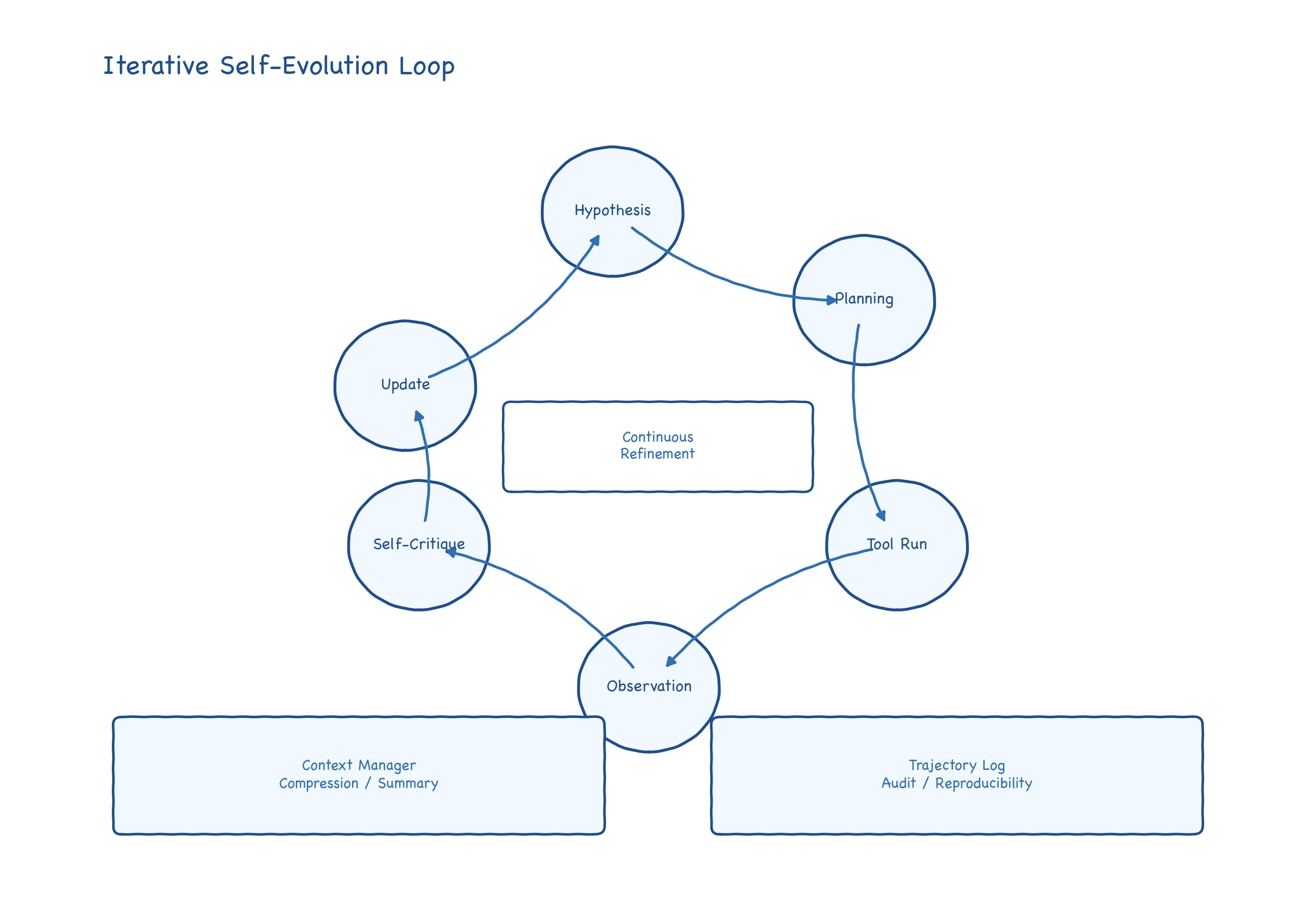
大语言模型(Large Language Model,LLM)在 EvoMaster 中并不是“唯一中心”,而是被放在统一抽象层中,供 Agent 通过统一接口调用。
段末注释:LLM 指能够进行自然语言理解、生成、推理与函数调用的大规模参数模型;后文沿用 LLM,不重复全称。
4. 能力层实现:Tools / Skills / LLM 三件套
4.1 Tools:动作执行与观测回传
Tools 模块采用标准的 Action-Execution-Observation 模式:Agent 决定调用哪个工具,工具执行后返回 observation,再进入下一轮推理。内置工具包括命令执行、编辑、思考、任务完成信号等。
模型上下文协议(Model Context Protocol,MCP)是 EvoMaster 扩展外部工具生态的关键通道。通过 MCPToolManager,外部 MCP 服务可被统一包装为本地可调用工具,并注册到 ToolRegistry。
段末注释:MCP 是一种让模型或 Agent 以标准化方式连接外部工具/服务的协议;后文沿用 MCP,不重复全称。
4.2 Skills:分层知识注入与按需加载
EvoMaster 的 Skill 系统在 v0.0.2 之后统一为单一 Skill 模型,强调三级信息结构:
- Level 1:
meta_info(常驻上下文,供 Agent 判断是否需要该技能) - Level 2:
full_info(按需加载详细文档) - Level 3:
scripts(可执行脚本,必要时通过工具调用)
这个设计的实用价值是“少占上下文、保留细节”:Agent 不必每轮背全部文档,只在需要时拉取细节或脚本执行。
4.3 LLM 抽象层:可替换后端与可控重试
EvoMaster 对不同模型提供统一接口(OpenAI、Anthropic、DeepSeek、OpenRouter 等),并封装了超时、重试、工具规范转换等逻辑。对于科研实验,这意味着你可以在基本不改业务逻辑的前提下做后端模型对照试验。
应用程序接口(Application Programming Interface,API)在该框架里被统一封装到 create_llm() 及各 Provider 实现中,简化了跨模型切换成本。
段末注释:API 指程序之间交互的调用接口;后文沿用 API,不重复全称。
5. 实验就绪(Experiment-Ready)是如何落地的?
很多 Agent 框架强调“能跑”,EvoMaster 更强调“能复现”:
- 配置驱动:核心行为通过 YAML 配置声明(每个 agent 的 LLM、tools、skills、max_turns 等)。
- 轨迹记录:每轮对话、工具调用、状态都可落盘,形成结构化审计日志(常见为 JavaScript 对象表示法,JavaScript Object Notation,JSON)。
- 运行目录规范化:每次运行自动生成 run 目录,保存配置副本、轨迹与工作区。
- 并行/批量任务支持:
run.py同时支持单任务、批任务、并行执行与多模态输入。
可扩展标记语言(YAML Ain’t Markup Language,YAML)在这里的意义不是“配置文件好看”,而是把实验变量管理从代码层抽出来,降低复现实验门槛。
段末注释:YAML 是一种人类可读的数据序列化格式,常用于配置文件;后文沿用 YAML,不重复全称。
6. 多智能体协同:EvoMaster 的第二进化轴
除了单 Agent 自迭代,EvoMaster 还强调“团队进化”:通过 AgentSlots 声明角色(如 Solver、Critic、Rewriter、Selector),让多个 Agent 在同一任务中分工协作、互相纠错。
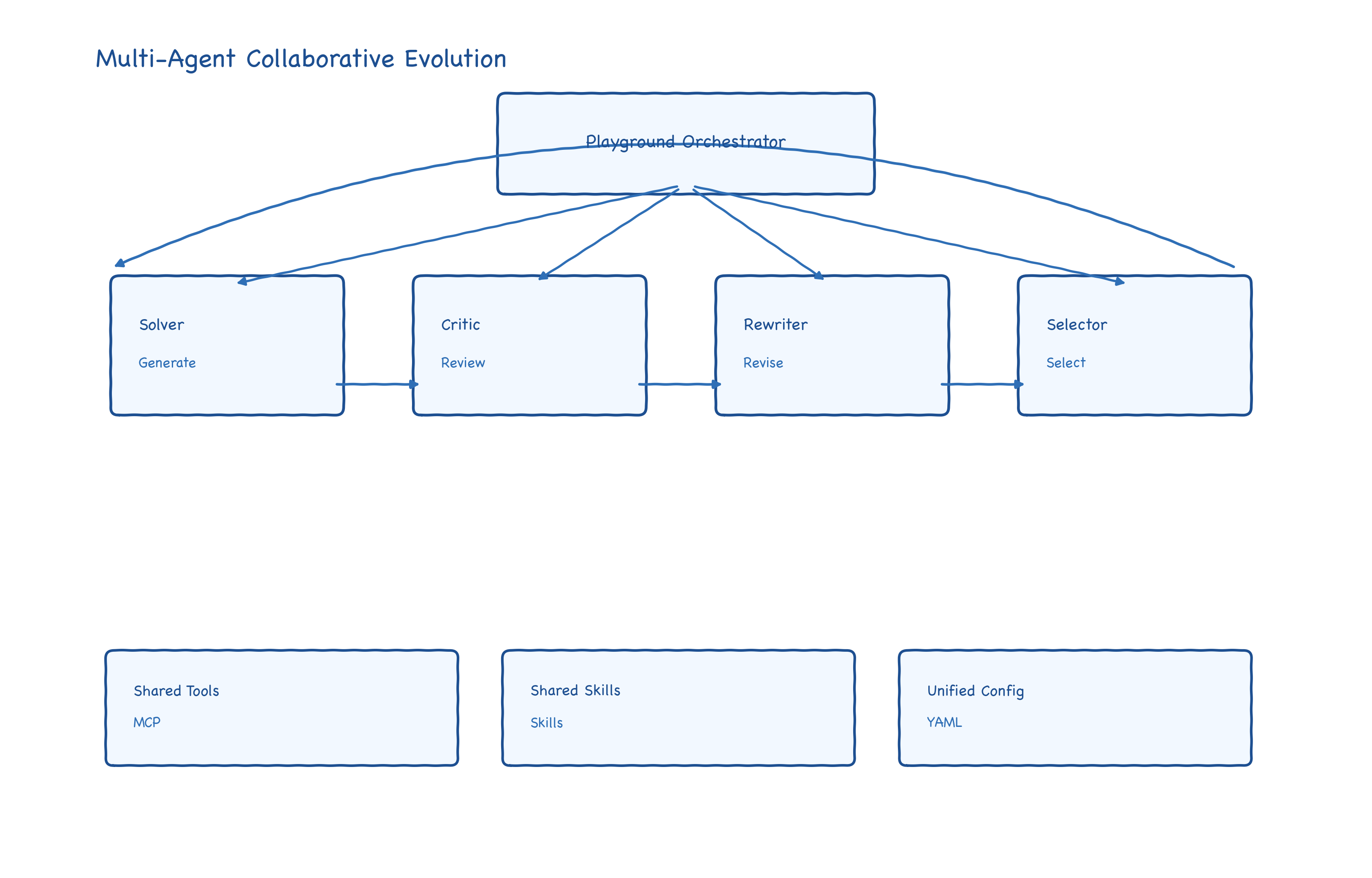
这类结构在复杂科研任务上很常见:一个 Agent 先提出方案,另一个专门找漏洞,第三个负责重写,最后由选择器综合决策。与“单点最强模型”思路相比,它更像科研团队的组织行为抽象。
7. 公开结果怎么看:不仅是分数,更是机制验证
根据论文披露,在与 OpenClaw(同 GPT-5.4 后端)对比中,EvoMaster 在 4 个基准上均显著领先:
- 人类终极考试(Humanity’s Last Exam,HLE): 41.1 vs 13.6(+202%)
- 机器学习工程基准轻量版(Machine Learning Engineering Benchmark Lite,MLE-Bench Lite): 75.8 vs 18.2(+316%)
- BrowseComp: 73.3 vs 28.3(+159%)
- FrontierScience: 53.3 vs 18.3(+191%)
这里真正值得关注的是“为何提升”:论文把收益归因于迭代流程与协同机制,比如 MLE-Bench 的多阶段改进流程、BrowseComp 的 planner-executor 循环、HLE 的 Solve-Critique-Rewrite-Select 管线。换句话说,EvoMaster 的优势主要来自系统设计,而非单次 prompt 技巧。
段末注释:JSON 常用于结构化日志存储;HLE 与 MLE-Bench Lite 分别对应跨学科知识与长程 ML 工程能力评测,后文沿用缩写。
8. 代码层面的“约 100 行可扩展”到底是什么意思?
官方反复提“约 100 行代码可搭建新 Agent”,本质上是因为框架把重复工程做了收敛:
- 有统一配置系统,不必每次手写参数解析;
- 有统一 Session 与工具注册,不必重复写环境桥接;
- 有统一 Agent 循环,不必重复写 tool loop;
- 有统一轨迹系统,不必每个项目另做日志标准。
因此这 100 行主要在写“领域编排逻辑”,而不是底座 plumbing。对科研团队而言,这意味着更快的问题验证周期。
9. 局限与实践建议
论文也明确了当前边界:EvoMaster 目前更偏 in-silico(计算实验)场景,和真实实验设备(如机器人实验台、自动化云实验室)的原生对接能力还在演进中。
我的实践建议是:
- 先从单 Agent + 少量高价值工具起步,建立可复现流水线;
- 再逐步引入 Critic/Reviewer 角色,验证多 Agent 协同增益;
- 把“轨迹分析”当作一等公民,持续提炼可复用策略到 skills;
- 用配置版本化管理实验,而不是在代码里散落改动。
10. 小结
EvoMaster 不是“又一个会调工具的 Agent 框架”,它更像一个面向科研任务的“演化执行底座”:通过三层解耦架构保证可扩展,通过上下文与轨迹系统保证长程可控,通过单体迭代与多体协作实现持续进化。如果你关心的是“如何把 Agent 从演示推进到可复现实验平台”,EvoMaster 提供了一条工程上相对完整且可落地的路径。