1. 文献与资源
| 类型 | 说明 |
|---|---|
| 论文 | Wang Y, et al. Accelerating primer design for amplicon sequencing using large language model-powered agents. Nat Biomed Eng (2025). DOI: 10.1038/s41551-025-01455-z |
| PubMed | PMID 40738975 |
| 代码 | melobio/PrimeGen |
| 补充材料 | 文章页 Additional/Supplementary/Source Data(以期刊页面更新为准) |
说明:该论文为期刊授权发布(非 CC BY 开放全文),本文配图用于学习解读,请按期刊版权条款规范使用。
2. 一句话定位
PrimeGen 是一个以 GPT-4o 为中央控制器的引物设计多智能体系统:把“需求理解→目标检索→引物设计→机器人脚本→实验异常检测→重设计”串成闭环,面向**靶向下一代测序(targeted next-generation sequencing,tNGS)**高重数面板设计。
段末注释:tNGS 指针对选定区域(而非全基因组)进行测序,常用于病原体分型、遗传病 panel、肿瘤靶向位点和耐药位点检测。
3. 系统架构:四个子智能体 + 一个控制器
PrimeGen 的控制器负责意图解析与任务编排,调用 4 个子智能体:
- Search Agent:从 NCBI、OMIM、COSMIC、ClinVar、CARD 等检索目标序列/位点
- Primer Agent:候选引物生成、打分、面板组合优化、重设计
- Protocol Agent:检索增强生成协议并输出可执行液体处理脚本
- Experiment Agent:视觉异常检测 + 错误纠正 + 回传反馈
文献原图(Fig. 1):PrimeGen 全流程工作图(论文主图)。
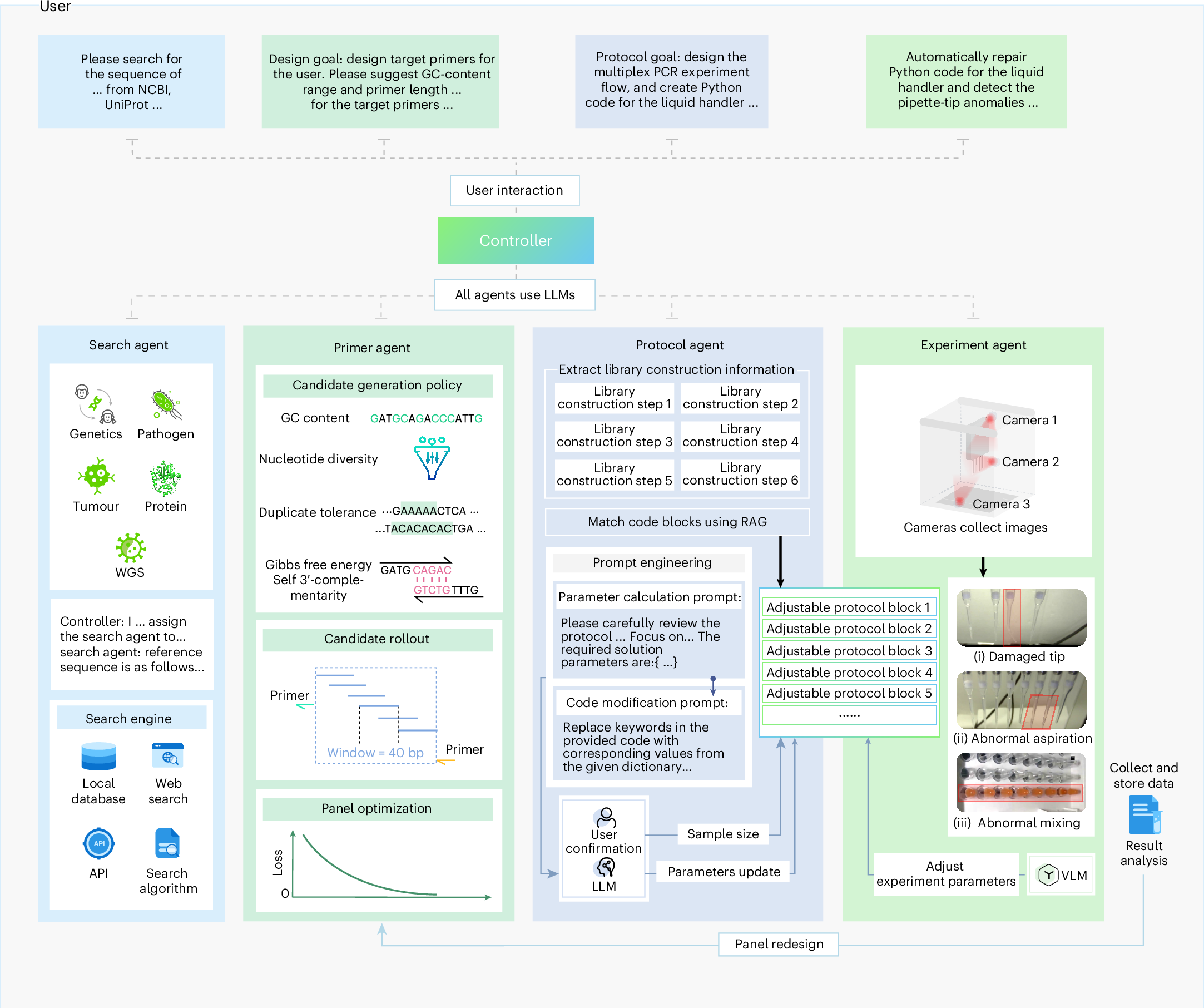
4. Primer Agent 的方法核心
4.1 候选生成:滑动窗口 + 约束筛选 + 松弛机制
在目标区间上采用滑动窗口生成候选,再按 GC、复杂度、二级结构与互补性等规则筛选;若局部连续失败,逐步放宽阈值,避免整段设计中断。
设目标区长度为 (L),窗口长 (w),步长 (s),窗口起点:
$$
t \in {0,s,2s,\dots}\cap[0,L-w]
$$
每个窗口内生成 forward/reverse 组合候选,进入面板级优化。
4.2 面板优化:组合爆炸下的启发式搜索
若第 (i) 个扩增子有 (a_i) 个候选引物对,搜索空间为:
$$
|\Omega|=\prod_{i=1}^{n}a_i
$$
面板优化目标可写作加权损失:
$$
\text{Loss}(P)=w_1,\phi_{\mathrm{dimer}}(P)+w_2\sum_{i=1}^{n}\psi_{\mathrm{off\text{-}target}}(A_i)
$$
其中 (\phi) 对应二聚体风险(文中基于 SADDLE 思路),(\psi) 对应 BLAST 脱靶风险项。
段末注释:SADDLE 为多重 PCR 面板优化相关算法框架;BLAST 为序列局部比对工具,此处用于非目标匹配惩罚。
4.3 LLM 作为优化器
论文把 LLM 优化器 与 Greedy、GA、AdaLead 对比:LLM 可一次联动修改多个扩增子位点的引物选择(而非单点微调),在高维组合空间中表现出较快收敛趋势与可用解质量。
文献原图(Fig. 2):Search/Primer agent 工作流与面板优化效果对比。

5. Protocol 与 Experiment Agent:把“设计”变成“可执行实验”
5.1 Protocol Agent
将引物面板与建库流程映射到可调代码块,通过 检索增强生成(retrieval-augmented generation,RAG) + 模板参数化输出机器人可执行脚本。
5.2 Experiment Agent
在液体处理过程中做视觉异常检测(吸头状态、孔板位置、混匀异常等),触发自动修复或人工介入,并把异常信息返回设计端用于下一轮优化。
段末注释:RAG 指“先检索知识片段,再条件生成”的流程,可降低纯生成式模型的事实漂移。
文献原图(Fig. 4):Protocol Agent 代码生成流程。
文献原图(Fig. 5):液体处理系统与异常检测流程。
6. 实验结果(论文主结论)
论文在 4 类任务展示了有效性(原文为准):
- SARS-CoV-2 全基因组面板(131 重):覆盖度与靶向表现优于/接近多种对照方案。
- ECS 多基因外显子 panel:高覆盖与低二聚体率。
- 结核分枝杆菌(MTB)耐药位点 panel:二轮优化后靶向率与均匀性提升。
- 酶突变质粒测序:重设计后目标区域覆盖进一步改善。
文献原图(Fig. 3):多场景实验结果统计图。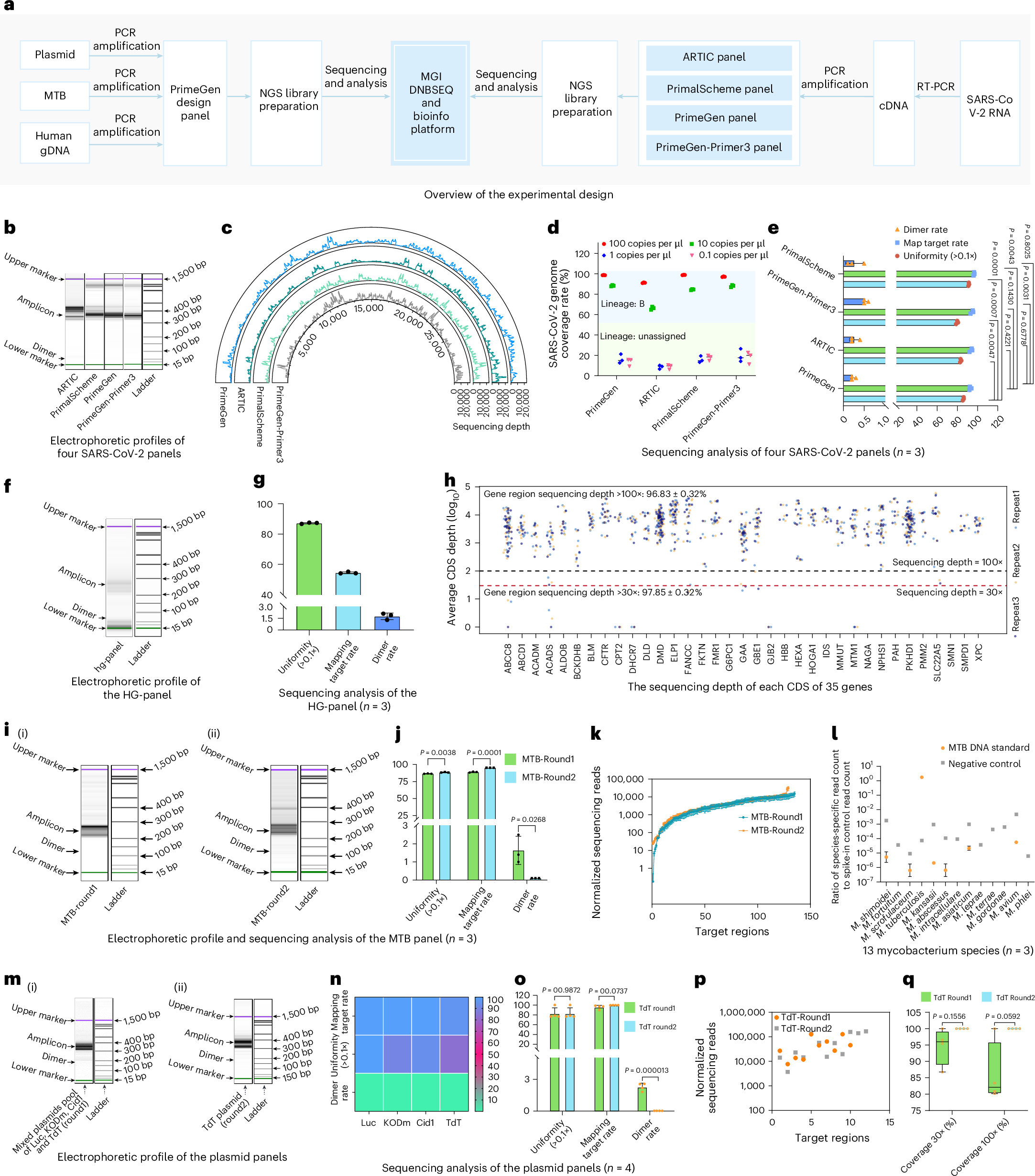
7. 与传统工具的关系(怎么选)
- PrimeGen 更适合:高重数 panel、需要机器人闭环、需要“自然语言→实验脚本”整链自动化的团队。
- Primer3/PMPrimer/PrimalScheme 更适合:单次、低重数、离线可复现实验设计。
- 现实约束:LLM API 成本、模型版本漂移、实验硬件门槛、合规(数据出境/隐私)。
8. 落地建议(面向实验室)
- 先把 PrimeGen 用在单一稳定场景(如单病原 panel)验证,再扩展到跨场景任务。
- 建立“自动建议 + 人工复核”门禁:重点复核脱靶、二聚体高风险、机器人体积边界。
- 将湿实验 KPI(MTR、均匀性、dimer rate、SMTR)标准化存档,便于多轮重设计。
- 对关键项目保留传统工具并行基线,避免全流程单点依赖。
9. 局限与风险
- 对闭源基础模型(如 GPT-4o)依赖较高,存在版本与成本波动。
- 组合优化与实验执行链路长,错误传播风险高。
- 异常检测与自动修复受实验室硬件条件影响较大。
- 非开放版权期刊图片不宜二次商用转载。
10. 参考链接
- PrimeGen 论文(Nature Biomedical Engineering, 2025)
https://doi.org/10.1038/s41551-025-01455-z - PrimeGen GitHub
https://github.com/melobio/PrimeGen - PubMed
https://pubmed.ncbi.nlm.nih.gov/40738975/