前置阅读:酶改造-模型论文-PLMs、酶改造-模型论文-ESM框架详解。本文配套公众号版本为「ESMFold2 全面解读」上篇。
缩写体例:缩写首次出现写「中文全称(英文全称,缩写)」;在该段末尾用 段末注释 框简要解释概念,后文沿用缩写。
2026 年 5 月 27 日,Nature 以一篇重磅报道宣告:蛋白质结构预测领域迎来了一位真正的挑战者。
它的名字叫 ESMFold2,来自一家成立不到两年、却已经融了 1.42 亿美元的公司——EvolutionaryScale。它的领军人物 Alex Rives 曾是 Meta 大模型团队的核心负责人,而这一次他选择押注的方向,是用语言模型「读懂」蛋白质。
Move over, AlphaFold: open source model predicts shape of 1 billion proteins.
这是 Nature 当时的标题,足够直白。我在第一时间把玩了一番,结合论文和官方 GitHub 的信息,决定把 ESMFold2 的来龙去脉、技术细节和湿实验结果全部整理成这篇,方便以后有需要时回查,也顺手分享出来。
一、ESMFold2 是什么?
ESMFold2 是一套蛋白质结构预测与设计模型,核心突破在于:它不仅仅是一个「结构预测工具」,而是一个真正在学习蛋白质「语言」的 world model。
它能预测:
- 蛋白质复合物(Protein-protein interaction, PPI)
- 抗体-抗原结合(Antibody-antigen complex)
- 蛋白-配体结合(Protein-ligand complex)
并且,在单序列(single-sequence,不需要 MSA)设定下,就能达到极具竞争力的精度。
它的底座是 ESMC(EvolutionaryScale Language Model of the Corpus),一个全新训练的蛋白质语言模型,参数量从 3 亿到 600 亿不等。训练数据达到了惊人的 28 亿条蛋白序列,是上一代 ESMFold(5000 万条)的 56 倍,其中包含大量宏基因组数据。
简单来说:ESMFold2 之所以「更懂蛋白质」,不是因为它有更复杂的结构建模技巧,而是因为它看过更多的蛋白质「句子」。
二、从 ESMFold1 到 ESMFold2:关键进化一览
| 维度 | ESMFold1 | ESMFold2 |
|---|---|---|
| 语言模型底座 | ESM2 | ESMC(3亿/6亿/600亿参数) |
| 训练数据 | ~5000 万条序列 | ~28 亿条序列(含宏基因组) |
| 主要能力 | 单链结构预测 | 复合物 + 抗体 + 蛋白-配体 |
| Pair 表征 | 简单配对 | 显式构建 + 循环更新 + 简化 Pair layer |
| 坐标生成 | Geometric Head | Diffusion Transformer(与 AF3 同范式) |
| 推理速度(1024 残基) | — | 15.8 秒(10 loops / 200 steps),Fast 版 9.4 秒 |
几个关键变化值得重点说:
语言模型底座的升级是根本性。ESMC 的预训练目标与 ESM2 不同,它在更大、更 Diverse 的数据上进行训练,这直接带来了泛化能力的跃升——尤其是对宏基因组来源的非典型蛋白质。
Pair 表征的重新设计是 ESMFold2 的核心创新之一。上一代的 pair 表征相对简单,ESMFold2 引入了显式构建 + 循环更新的机制,Pair layer 也大幅简化——只保留了三角形乘法(triangle multiplication)和前馈跃迁(feedforward transition)两种操作,去掉了 ESMfold1 中更复杂的组件。
Diffusion Transformer 的引入则是与 AlphaFold3 走在了同一条路上。用扩散模型逐步从噪声还原三维坐标,相比 geometric head 的直接预测,生成质量更稳定,对多链复合物的处理也更好。
三、架构解析:ESMC + Pair layer + Diffusion
ESMFold2 的推理流程分为两个主要阶段:
3.1 表征学习阶段
蛋白质序列首先被 token 化(每个氨基酸为一个 token),送入 ESMC 语言模型进行编码。ESMC 的输出包含:
s(per-token 表征):每个氨基酸的位置特征
z(pairwise 表征):所有氨基酸两两之间的交互特征
这两个表征随后进入 Pair layer 模块进行多轮(默认 10 轮)迭代更新。在每一轮中,pair 表征通过三角形乘法和前馈跃迁不断精炼,最终得到高质量的配对信息。
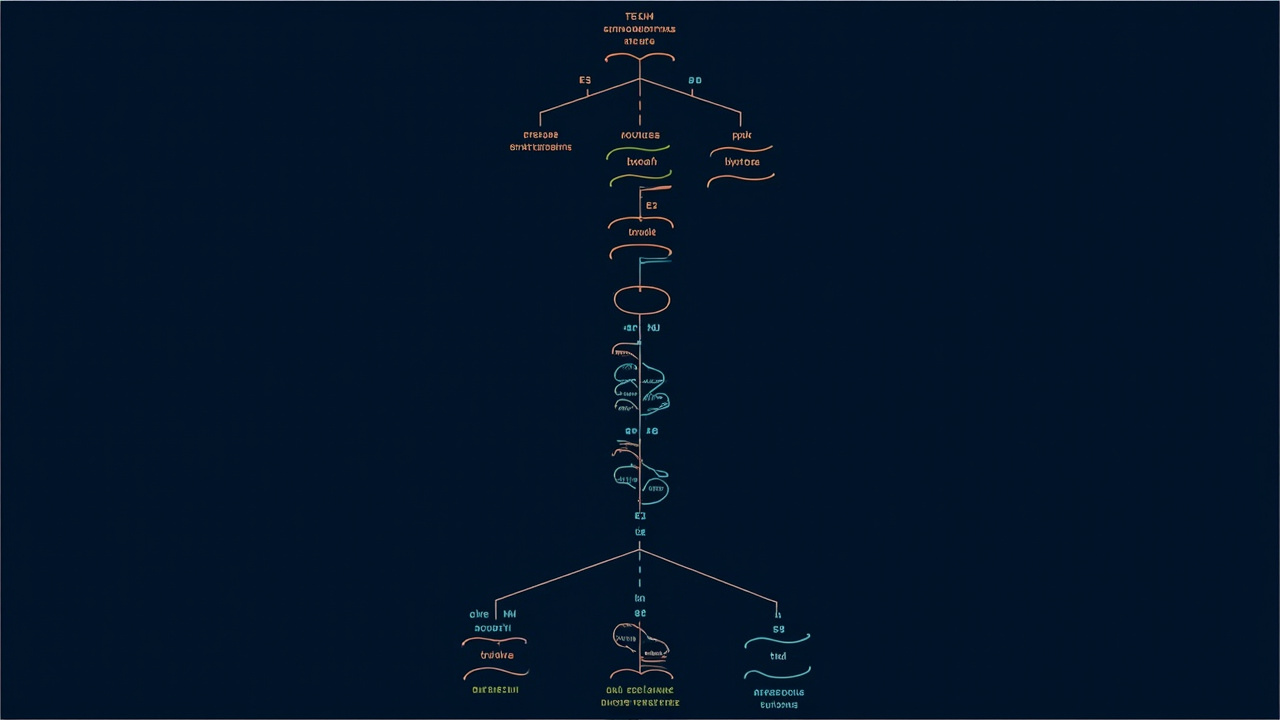
3.2 坐标生成阶段
Pair layer 的输出(s, z)作为条件(conditioning)送入 Diffusion Transformer。
扩散过程从随机噪声开始,逐步去噪生成三维原子坐标。默认配置是 10 个 loops、每个 loop 200 步 diffusion,总计约 2000 步。如果追求速度,可以使用 Fast 版本(约 9.4 秒/1024 残基),精度损失在可接受范围内。
四、Benchmark 表现:单序列也能打
ESMFold2 最重要的特点之一是:单序列(single-sequence)设定下就能达到很高的精度,这与依赖 MSA(多序列比对)的 AlphaFold 系列形成鲜明对比。
| 基准测试 | ESMFold2(单序列) | ESMFold2(+MSA) | 说明 |
|---|---|---|---|
| FoldBench antibody-antigen | 50% ± 2% DockQ | 53% ± 2% DockQ | 抗体-抗原复合物 |
| PPI | 70% ± 1% | 76% ± 1% | 蛋白-蛋白相互作用 |
| Protein-ligand | 57% ± 1% | — | 蛋白-小分子配体 |
DockQ 是评估蛋白质复合物预测质量的核心指标,> 0.23 通常被认为是「可接受」,> 0.49 是「较好」,> 0.8 是「接近实验精度」。
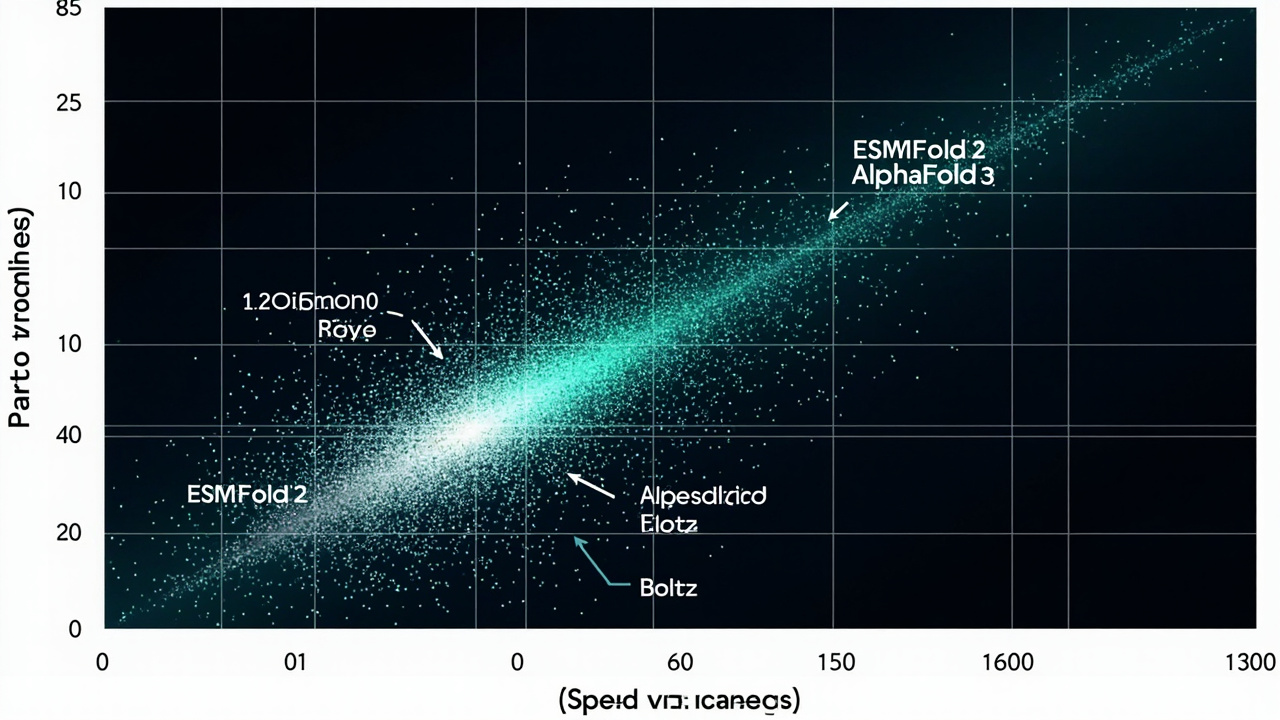
从速度-精度的 Pareto frontier 来看,ESMFold2 稳稳占据了右上角的位置——这是目前最快的高精度方案之一。
ESMFold2 不是去替代 AlphaFold3,而是在很多场景下提供一个「速度够快、精度够用」的选择。尤其是当你要跑 1000 条序列的高通量筛选时,ESMFold2 的推理速度优势是决定性的。
五、湿实验验证:5 靶点,全部验证有效
这是 ESMFold2 最让人印象深刻的部分:论文报告了 5 个靶点的湿实验验证,全部来自真实的 wet lab 数据。
| 靶点 | 设计类型 | 实测亲和力 |
|---|---|---|
| EGFR | Minibinder | ~0.29 nM |
| CTLA-4 | Minibinder | ~0.068 nM |
| PD-L1 | Minibinder | ~1.7 nM |
| PDGFRβ | Minibinder | 设计验证中 |
| CD45 | Minibinder | 设计验证中 |
几个关键数据:
- 微结合物(minibinder)平均成功率:54% → 70%(随着推理算力提升)
- 单链抗体(scFv)平均成功率:12.1% → 21.0%(同样是算力提升带来的收益)
- EGFR-minibinder 的 Cryo-EM 验证 RMSD:1.204 Å(与计算模型高度吻合)
1.2 Å 的 RMSD 意味着计算预测的结构和真实实验观测到的结构几乎完全重叠。这个精度放在业界是属于第一梯队的。
整个候选生成流程约 2 天(高度可并行),评分不到 1 天——对于一个需要合成、表达、纯化、检测的多步骤流程来说,这个速度已经是工程上的突破。

六、推理速度与算力门槛
ESMFold2 提供了两个版本:
| 版本 | 推理步数 | 速度(1024 残基) | 精度 |
|---|---|---|---|
| 标准版 | 10 loops × 200 steps | ~15.8 秒 | 最高 |
| Fast 版 | 10 loops × ~100 steps | ~9.4 秒 | 略有下降 |
Fast 版将 diffusion 步数减半,速度几乎快了一倍,而 benchmark 精度损失在 1–3 个百分点之间。对于早期筛选场景,这个 trade-off 非常划算。
在消费级 GPU(如 A100 40GB)上,1024 残基的推理约需 15–20 秒。更大的蛋白(2048+ 残基)会成比例增加内存和耗时,但仍在可接受范围内。
七、冷静看:边界与局限
ESMFold2 很强,但它不是万能的。以下几点值得注意:
1. 静态结构 ≠ 真实动态
ESMFold2 预测的是静态构象。蛋白质在细胞内是不断运动的,有构象变化(conformational change)、有翻译后修饰(PTM)、有浓度效应。模型给出的只是一个「快照」。
2. 极端非典型结构仍有风险
这是 ESMFold1 的老问题了——对于在训练数据中极少出现的折叠类型,模型的表现会明显下滑。宏基因组数据虽多,但仍有覆盖盲区。
3.「概念」不等于物理机制
论文用 Sparse Autoencoder 找到了 ESMC latent space 中可解释的概念方向(catalytic motif、beta barrel 等),但这些「概念」是统计结构的产物,不等于真正的物理机制。
4. Sergey Ovchinnikov(MIT)的评价
这位 AlphaFold 系列的核心贡献者说得中肯:ESMFold2 是补充,不是替代。AlphaFold3 在高精度小分子/离子结合、细节结构上仍然更强;ESMFold2 则在宏基因组泛化、高通量筛选、抗体设计上更有优势。
八、结语
如果你在找的是一个「速度够快、精度够用、开源可用」的结构预测工具,ESMFold2 值得你花时间了解。
它用 28 亿条序列训练出的语言模型直觉,配合 Diffusion Transformer 的生成能力,以及经过湿实验验证的抗体/复合物设计表现,证明了一条与 AlphaFold 不同的路线:不是更复杂的结构建模,而是更深的语言理解。
蛋白质折叠的规律,也许真的写在那本 28 亿「句子」的语言书里。
GitHub 地址:github.com/EvolutionaryScale/ESMFold(已开源)
还想看什么?ESM Atlas 的使用指南、ESMFold2 与 AlphaFold3 的详细横评、或是抗体设计实操流程——哪篇先出,欢迎留言告诉我。