1. 文献信息
- 题目:UniKP: a unified framework for the prediction of enzyme kinetic parameters
- 期刊:Nature Communications,2023 年 12 月 11 日;卷 14,文章号 8211
- DOI:https://doi.org/10.1038/s41467-023-44113-1
- 开放获取:PMC PMC10713628,PMID 38081905
- 通讯作者:深圳先进技术研究院等,罗小洲(Xiaozhou Luo) 等
- 并列一作:余晗(Han Yu)、邓华祥(Huaxiang Deng)
酶动力学参数主要包括周转数(turnover number,kcat)、米氏常数(Michaelis constant,Km) 以及二者比值表示的催化效率(catalytic efficiency,kcat/Km)。UniKP 的目标是从蛋白质序列与底物结构出发,在统一框架内同时提升上述量的预测精度,并衍生 EF-UniKP(考虑 pH、温度 等环境因素)与高 kcat 区间的样本重加权策略。
段末注释:kcat 为饱和底物下每活性位点每秒转化底物数的上限;Km 为半饱和底物浓度;kcat/Km 综合反映底物亲和力与催化速率(同一底物比较时常用)。
2. 研究动机与定位
UniProt 等序列库规模达数亿条,而 BRENDA、SABIO-RK 等中实验测得的 kcat、Km 仅数万量级,标注稀疏制约代谢工程、定向进化等应用。既有工作往往分别预测 kcat 或 Km,再用独立模型结果相除得到 kcat/Km,与直接实验测定的 kcat/Km 一致性差(文中展示相关系数可接近 0)。此外,pH、温度 等环境因子影响显著,而多数模型未显式纳入。
UniKP 的定位是:**用预训练语言模型分别编码酶序列与小分子底物,再拼接为固定维向量,由可解释的集成学习(以 极端随机树(Extremely Randomized Trees,Extra Trees) 为主)统一拟合 kcat、Km 或 kcat/Km,从而在「小样本、高维特征」条件下取得优于纯端到端深度网络(在作者对比设定下)的泛化表现。
段末注释:Extra Trees 与随机森林同属树集成,但在划分点选择上引入更强随机性,常能降低方差;此处强调作者系统比较后选用该基学习器。
3. 框架概览(对应原文 Fig. 1)
UniKP 由 表征模块(representation module) 与 机器学习模块(machine learning module) 组成。
3.1 酶序列表征:ProtT5-XL-UniRef50
- 使用 ProtT5 系列的 ProtT5-XL-UniRef50 预训练模型(ProtTrans 路线),将每个氨基酸残基映射为最后一层隐藏状态上的 1024 维向量。
- 对整条序列做 平均池化(mean pooling) 得到 1024 维整条蛋白表征(作者引用指出 mean pooling 对「整条蛋白」级任务效果较好)。
3.2 底物表征:SMILES Transformer
- 底物以 SMILES(Simplified Molecular Input Line Entry System,SMILES) 表示,输入预训练的 SMILES Transformer(Honda 等)。
- 每个 SMILES 符号对应最后一层 256 维向量;将最后一层的 mean pooling 与 max pooling,以及倒数第二层与最后一层的「首位置输出」等拼接,得到 1024 维分子级表征(与原文 Fig. 1b 一致)。
段末注释:SMILES 为线性分子编码;mean/max pooling 将变长序列压成定长向量。
3.3 读出层:Extra Trees 等
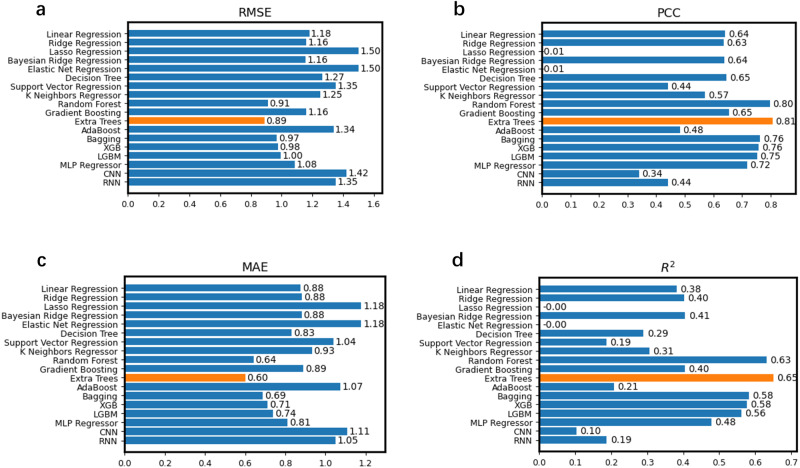
- 将 1024(酶)+ 1024(底物)= 2048 维向量拼接后,输入下游回归器。作者在 16 种经典机器学习模型与 2 种深度学习基线(CNN、RNN)上做了系统比较(原文 Fig. 2),在默认超参、未针对集成学习细致调参的前提下,Extra Trees 的 R² 等指标最高(kcat 任务五折交叉验证示例中 Extra Trees R² ≈ 0.65,而线性回归约 0.38,CNN/RNN 表现较弱)。作者讨论认为:数据规模约 10⁴、特征维 2048,树模型更适合「高维、小样本」且无需大量调参;深度网络则更依赖标注规模与结构设计。
3.4 表征必要性(t-SNE)
- 作者将仅拼接的 2048 维向量做 t-SNE(t-distributed stochastic neighbor embedding,t-SNE) 可视化,显示其对高/低 kcat 区分度不足(Supplementary Fig. 1),从而说明必须依赖后续机器学习模块而非仅靠表征拼接。
段末注释:t-SNE 为非线性降维可视化工具,用于观察聚类与可分性。
文献原图(Fig. 1):UniKP 总览——ProtT5 序列支路、SMILES Transformer 底物支路、Extra Trees 预测 kcat、Km、kcat/Km,以及 EF-UniKP 与重加权扩展。(图源:Yu 等,Nat Commun 2023,PMC 10713628,CC BY 4.0)
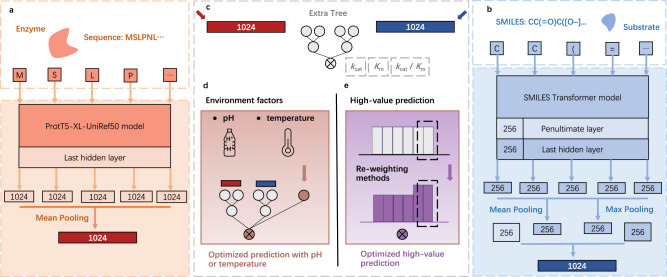
4. 详细 Methods:数据集与预处理
4.1 DLKcat(kcat 主实验)
- 来源与 DLKcat 论文一致:自 BRENDA、SABIO-RK 等整理的酶–底物–kcat。
- 剔除底物 SMILES 含 「.」(多组分)或 kcat ≤ 0 的样本后,共 16 838 条;kcat 取对数刻度建模。
- 划分:90% 训练 / 10% 测试,随机重复 5 次,与 DLKcat 原文可比。
4.2 pH 与温度数据集(EF-UniKP)
- 酶序列、底物名及 pH 或反应温度来自 UniProt;底物结构由 PubChem 检索并转 SMILES。
- pH 集:636 条,pH 约 3–10.5;温度 集:572 条,约 4–85 °C。
- 独立划分:80% 训练 / 20% 测试(EF-UniKP 训练另有子划分,见 §6)。
4.3 Km 数据集
- 采用 Kroll 等 PLoS Biol. 2021 中 11 722 条天然酶–底物 Km 数据;底物改为 SMILES 表示,Km 取 log10;80/20 划分与原文对齐。
4.4 kcat/Km 数据集
- 自 BRENDA、UniProt、PubChem 整理 910 条酶序列、底物结构与实验 kcat/Km;五折交叉验证评估。
5. 原文 Methods:UniKP 与 EF-UniKP 的构建
5.1 实现环境
- PyTorch 1.10.1+cu113,scikit-learn 0.24.2(表征与训练管线);部分对比实验使用 sklearn 1.1.1。硬件:Ubuntu 20.04,64 核 CPU,4× NVIDIA GeForce RTX 3080(文内训练使用单核单卡)。
5.2 机器学习模块的模型清单(原文)
- 16 种机器学习:线性回归、Ridge、Lasso、Bayesian Ridge、Elastic Net、决策树、支持向量回归(Support Vector Regression,SVR)、K 近邻回归、随机森林、梯度提升、Extra Trees、AdaBoost、Bagging、XGBoost、LightGBM、浅层 MLP Regressor(视作传统机器学习)。
- CNN:一维卷积(16 通道、核 3)+ MaxPool + 全连接(16×1023 → 64 → 1)。
- RNN:输入维 2048,128 隐藏单元,1 层 RNN + 两层全连接(128→64→1)。
- 深度学习训练:Adam,学习率 1×10⁻⁴,损失 MSE,batch size 8192,PyTorch 1.10.1。
5.3 EF-UniKP(两层框架)
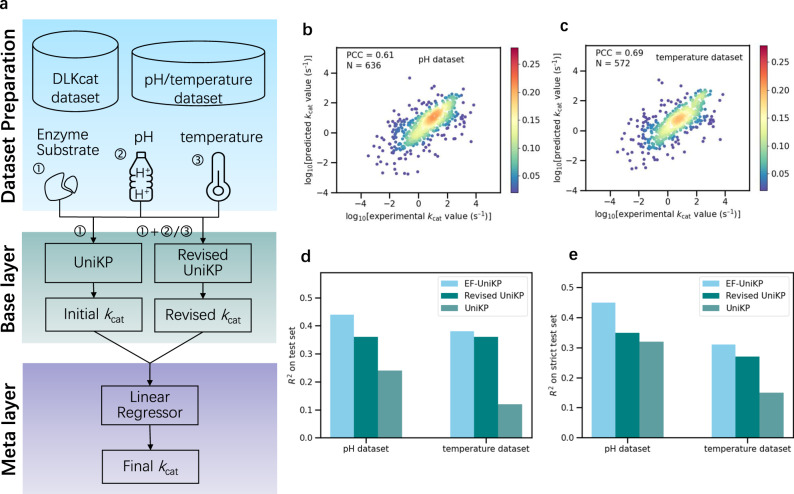
- 底层:模型 A 为在无环境标签的 DLKcat 上训练的 UniKP;模型 B 为 Revised UniKP,输入为酶+底物表征再拼接标量 pH 或 温度,同样用 Extra Trees。
- 元学习层:以 A、B 输出的 kcat 预测值为特征,训练线性回归融合为最终 kcat。
- 训练数据划分:在 pH/温度 全集上先 80% 训练 / 20% 测试;训练部分再分为 64% / 16% 两段:第一段训练 Revised UniKP,第二段结合两底层输出训练元层线性模型。测试在剩余 20% 上评估;随机划分重复 3 次取平均以降低划分偶然性。
5.4 高 kcat 样本重加权
- 针对 kcat 标签分布近似正态、高值端样本少的问题,比较 DMW、CSW、CBW、LDS 四类代表性重加权(见 Yang 等 ICML 2021 不平衡回归脉络)。
- DMW:直接提高 log kcat > 4 样本权重,网格搜索倍率 2–100 等,最优约为权重 ×10 且不做归一化等(原文 Methods 细述 12 组组合)。
- CSW:按 131 个等宽区间计数,root CSW 等变体中 root CSW 较优。
- CBW:有效样本数 (E_n=(1-\beta^n)/(1-\beta)),β 网格搜索后 0.9 最优。
- LDS:对标签经验分布与高斯核卷积得平滑密度;核宽 5、σ=1 较优。
5.5 评价指标(原文 Eq. 1–4)
- R²、PCC、RMSE、MAE(mean absolute error,MAE);变量记号 yei(实验)、ypi(预测)等见论文。
5.6 可解释性:SHAP
- 对测试集上训练好的 UniKP(TreeExplainer)计算 SHAP(SHapley Additive exPlanations,SHAP) 值,分析 2048 维中酶相关维与底物相关维的贡献(原文 Fig. 3f:Top 20 特征中多数来自酶嵌入)。
5.7 湿实验与挖掘协议(节选)
- BLASTp:以 RgTAL 为查询,nr 库取 E-value 排序前 1000,默认 BLOSUM62、word size 5、expect 0.05。
- 动力学测定与 HPLC 条件见原文 Methods(缓冲液、波长、梯度等)。
段末注释:SHAP 基于合作博弈 Shapley 值解释单条预测中各特征的边际贡献。
6. 主要结果(概括)
6.1 kcat:相对 DLKcat
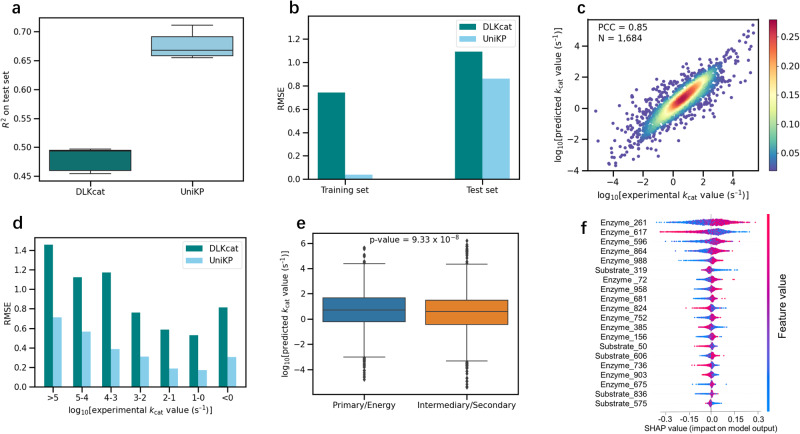
- 五轮随机划分测试集平均 R² ≈ 0.68,较 DLKcat 报告值高约 20%;测试集 PCC ≈ 0.85;更严格「酶或底物未在训练中出现」子集上 PCC 亦优于 DLKcat(原文 Fig. 3、Supplementary Fig. 2)。
- 与实验几何均值对照(用于讨论数据泄漏)显示 UniKP 更优(Supplementary Fig. 3)。
文献原图(Fig. 2):16+2 种模型在 RMSE、PCC、MAE、R² 上的对比(五折交叉验证)。
文献原图(Fig. 3):与 DLKcat 的 R²、RMSE、测试集散点、分 kcat 区间 RMSE、代谢路径分类 t 检验、SHAP 等。
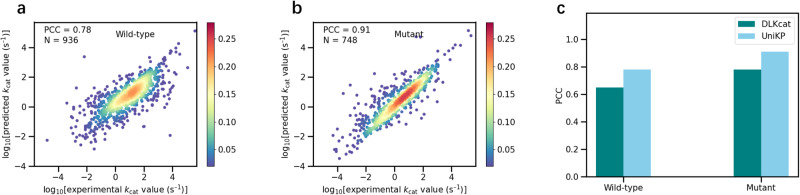
6.2 野生型与突变体
- 测试集:野生型 PCC ≈ 0.78,突变体 ≈ 0.91;整体优于 DLKcat(原文 Fig. 4)。
文献原图(Fig. 4):野生型 / 突变体散点及 PCC 柱状对比。
6.3 EF-UniKP
- Revised UniKP 在 pH、温度 集上单独已有一定 PCC/R²;EF-UniKP 在独立测试集上多数指标优于单层 UniKP 或 Revised UniKP,在「酶或底物未出现于训练」子集上仍保持优势(原文 Fig. 5)。
文献原图(Fig. 5):EF-UniKP 结构示意图及 pH/温度 性能。
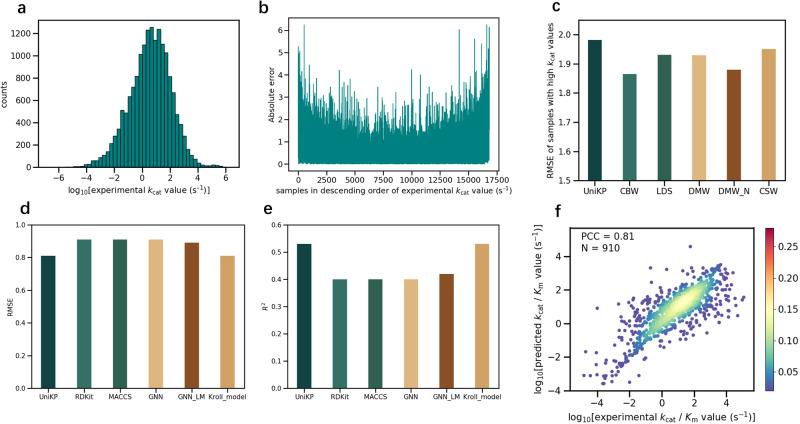
6.4 重加权与 Km、kcat/Km
- CBW 对 log kcat > 4 的高值子集 RMSE 改善约 6.5%(相对初始 UniKP)。
- Km:测试集 R² ≈ 0.53,PCC ≈ 0.73,与当时最强基线可比或更优。
- kcat/Km:PCC ≈ 0.81,R² ≈ 0.65;用「独立 kcat 预测 ÷ 独立 Km 预测」计算的比值与实验 kcat/Km 几乎无相关(PCC ≈ −0.02),凸显对 kcat/Km 做统一建模(而非两模型商)的必要性。
文献原图(Fig. 6):kcat 分布、逐样本误差、重加权 RMSE、Km 与 kcat/Km 结果。
6.5 应用:酪氨酸解氨酶(TAL)
- 挖掘:BLASTp 前 1000 条中用 UniKP 预测 kcat,实验验证 AsTAL 等(原文 Table 1)。
- 定向进化:单点饱和 19×693 = 13 167 突变体 in silico 筛选,发现 kcat/Km 显著提升的突变体。
- EF-UniKP:在 pH 9.5 等条件下对 TALclu 类似策略挖掘,HiTAL、TrTAL 等动力学优于野生型对照。
7. 与 DeepEnzyme、DLKcat 等的关系(阅读笔记)
- DLKcat:UniKP 使用同一 DLKcat 数据管线做主对比,强调预训练序列/分子表征 + 浅层集成学习相对 DLKcat 卷积式深度模型的增益。
- DeepEnzyme(Brief Bioinform 2024):在 DeepEnzyme 讨论中指出,UniKP 在部分指标上精度更高,但 DeepEnzyme 在突变效应定性排序等任务仍有特点,且结构已给定时 DeepEnzyme 推理可快数个数量级——二者取舍取决于是否需要三维结构、算力预算与任务类型。
8. 局限(原文 Discussion 归纳)
- 标注量相对序列宇宙仍极少;高 kcat 预测经重加权仅适度改善,未来可结合 SMOTE 等过采样与迁移/强化学习等。
- kcat 与 Km 若未来有同一批实验成对测定的统一大数据,「分别预测再相除」与「直接预测 kcat/Km」的差距可能缩小。
- 利益冲突声明见原文(作者与生物科技公司关系)。
9. 代码、数据与补充材料
- 代码与说明:https://github.com/Luo-SynBioLab/UniKP
- 预训练与权重:仓库说明需另行下载 ProtT5-XL-UniRef50(Zenodo 等链接见 README)、SMILES Transformer(DSPsleeporg/smiles-transformer),以及 UniKP 推理权重(Hugging Face:HanselYu/UniKP)。输出为 log10 尺度时需按说明反变换回物理单位。
- Zenodo 归档:https://doi.org/10.5281/zenodo.10115498(正文 Data availability 亦出现
10.5281/zenodo.1011549853写法,以作者仓库与 Zenodo 页面为准) - PDF(PMC):https://pmc.ncbi.nlm.nih.gov/articles/PMC10713628/pdf/41467_2023_Article_44113.pdf
- 补充信息:Supplementary PDF
- Source Data:ZIP
10. 与酶改造实践的关联(一句话)
需要同时关心 kcat、Km 与 kcat/Km、且希望仅用序列 + 底物 SMILES(无需先算蛋白三维结构)时,UniKP 是当前文献中较完整的统一管线;若强调远缘序列下的结构先验或位点级解释,可并列参考 DeepEnzyme 等结构增强模型。