在 大语言模型(large language model,LLM)应用中,编排(orchestration)指:在何时、以何种顺序、在何种失败与人工介入策略下,调用模型、工具、检索与外部系统,并把中间状态可靠地交给下一步。它与「写一段 prompt(提示词)」不同,关注的是控制流、状态与可恢复性。
段末注释:编排框架提供「表达控制流 + 绑定运行时能力」的抽象;选型本质是问题形状与框架假设是否匹配。
下文配图均为科普示意,便于建立心智模型,非各厂商官方架构图。
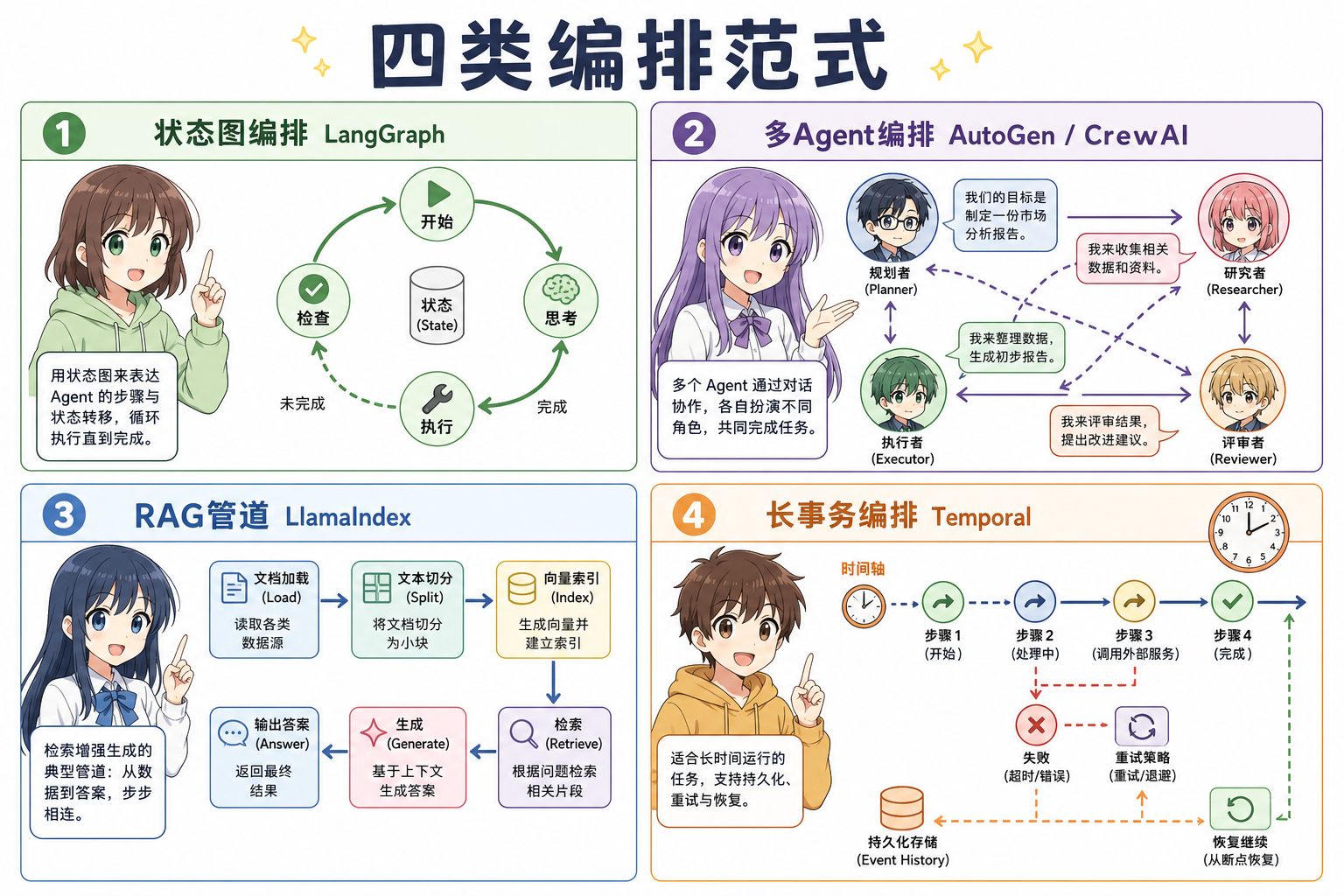
1. 为什么要单独谈「编排」
典型 LLM 应用已超出「一问一答」:多步工具调用、分支与回退、人在回路(human-in-the-loop,HITL)、长事务(跨分钟/小时/天)与可观测性(日志、指标、trace)都要求把逻辑从「提示词里的隐式流程」抽成显式或可执行的流程模型。
没有编排层时,常见痛点包括:
- 逻辑散落在
if/else与字符串拼接中,难以测试与审计; - 重试、幂等、超时与「从哪一步恢复」手写成本高;
- 多 Agent 协作时,消息路由与状态同步易失控。
编排框架的价值,在于用一套惯用抽象降低上述工程成本;不同框架的抽象不同,因此没有 universally 最优,只有更匹配场景。
2. 四大范式:怎么实现、强在哪、用在哪
2.1 有环状态图 + 显式状态(代表:LangGraph)
- 实现方法:把应用建模为节点(node)、边(edge)与共享 State(常
TypedDict+ reducer);支持条件边、自环(工具失败再回到规划);compile 时注入 checkpointer,用thread_id隔离会话与断点。 - 核心优势:控制流即文档;checkpoint 一等公民,利于 HITL、容错与多轮会话;与 LangChain 工具链集成深。
- 主要场景:ReAct(reason + act)类 Agent、需审批的高风险动作、复杂 RAG 路由、要「从某步重放」的调试与恢复。
- 选型注意:学习曲线与生态版本绑定;简单单次问答不必上图。
2.2 多智能体对话 / 事件驱动(代表:AutoGen、CrewAI、OpenAI Agents SDK)
- 实现方法:以 Agent 为对象,用消息传递、handoff(交接)、群聊或「角色 + 任务队列」组织协作;编排有时是声明式配置(角色、目标、工具列表),有时是事件循环里动态调度。
- 核心优势:多角色分工直观,原型快;AutoGen 偏灵活对话,CrewAI 偏「班组流水线」;OpenAI Agents SDK 轻量、与 OpenAI 模型/追踪贴合。
- 主要场景:研究助理、分工明确的内容生产、Agent 间需要协商或串行的任务链。
- 选型注意:要自建成本护栏(循环、重复调用)、可观测性与权限边界;生产上常与 Temporal 等组合做长事务外壳。
2.3 检索 / NLP 管道式编排(代表:LlamaIndex Workflows、Haystack)
- 实现方法:把 Retriever(检索器)、reranker、LLM、parser 连成 Pipeline 或事件工作流;强调数据块、索引与 RAG(retrieval-augmented generation)各阶段的类型与回调。
- 核心优势:与企业知识库、结构化解析同一生态;适合「检索 → 重排 → 生成 → 引用校验」这类偏 DAG(有向无环图)的流程。
- 主要场景:文档问答、客服知识库、合规引用链;分支相对有限、环较少时非常顺手。
- 选型注意:强 Agent 自环重试 时可能仍要引入图编排或外层状态机。
2.4 通用分布式工作流 / 长事务(代表:Temporal、Prefect、云 Step Functions)
- 实现方法:把每一步写成可重入的工作流函数,由运行时持久化历史、调度重试与补偿(saga);DAG 或状态机由平台保证至少一次/恰好一次语义(依配置)。
- 核心优势:小时级流程、人工作业节点、跨服务编排、版本化工作流与运维成熟;LLM 只是其中一步。
- 主要场景:订单/审批、ETL + 周期性报告、ML 训练流水线、任何「不能丢进度」的长流程。
- 选型注意:不自带 RAG/工具协议全家桶,LLM 侧常仍用 LangChain/SDK 写在活动(activity)里。
2.5 低代码与集成编排(代表:n8n、Make、Zapier)
- 实现方法:拖拽节点,用 HTTP、Webhook、SaaS 连接器串联;逻辑以画布保存。
- 核心优势:非研发也能改流程;对接千种 SaaS 快。
- 主要场景:运营自动化、轻量通知与同步、原型验证。
- 选型注意:复杂分支测试、Code Review、类型安全通常弱于代码框架;敏感数据出境与合规需单独评估。
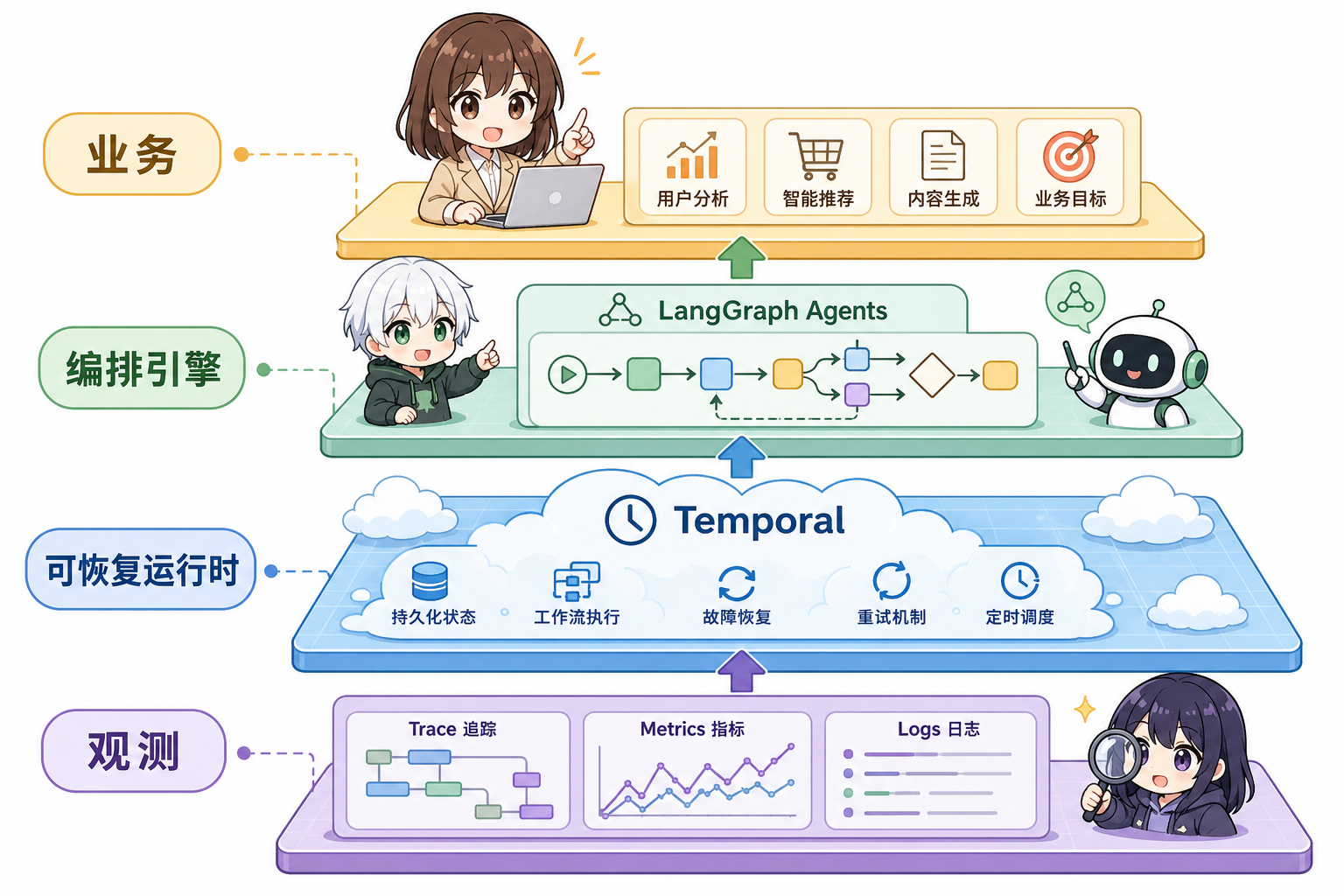
3. 横向对比表(速查)
| 维度 | 状态图类(如 LangGraph) | 多 Agent(如 CrewAI / AutoGen) | RAG 管道(如 LlamaIndex / Haystack) | 长事务工作流(如 Temporal) |
|---|---|---|---|---|
| 控制流表达 | 图 + 条件边 + 环 | 对话 / 任务 / 事件 | 多为 DAG 或弱环 | DAG + 平台级重试 |
| 状态与持久化 | State + checkpoint | 各框架不一,常需自补 | 管道上下文 + 外部存储 | Durable history 为核心 |
| HITL | 原生模式多 | 可建,需设计 | 多为简单中断 | Signal / 人任务节点成熟 |
| 与 LLM 生态 | LangChain 深 | 广 | 检索侧强 | 无绑定,自接 SDK |
| 典型风险 | 过度设计 | 成本与循环 | 过度复杂索引 | 学习曲线与基础设施 |
4. 如何做选型:建议维度
建议按下面顺序自问;越靠前的维度越应先定,避免先看框架再看问题。
- 流程是否有环(工具失败重试、多轮辩论、自修正):强环优先考虑状态图类;弱环 DAG 可考虑管道或 Temporal。
- 单次调用还是长事务(跨会话、跨天、要补偿):长事务优先考虑 Temporal / 云状态机,LLM 编排层叠在其上。
- 主导是「多角色协作」还是「单线程状态机」:前者看 CrewAI / AutoGen / OpenAI Agents SDK;后者看 LangGraph。
- 主导是「企业知识检索」还是「通用工具 Agent」:前者优先 LlamaIndex / Haystack + 必要时补图编排。
- 合规与审计:需要「每一步可证明、可回放」时,显式图 + checkpoint 或 Temporal 历史比纯对话 Agent 更易举证。
- 团队技能栈:.NET 企业可评估 Semantic Kernel;已深度 LangChain 则 LangGraph 迁移成本低。
- 运维与托管:是否必须 K8s、是否已有云厂商锁定,会倒推 Step Functions / Argo 等选项。
4.1 决策思路(Mermaid)
下列流程图用 camelCase 节点 ID,便于在支持 Mermaid 的渲染器中直接显示。
1 | flowchart TD |
段末注释:DAG 指有向无环图;saga 指通过补偿事务拆分长业务的一种模式。
5. 组合式架构(生产常见)
现实项目常分层:外层 Temporal 管「订单状态、付款回调、超时」;内层 LangGraph 管「单轮 Agent 推理与工具」;RAG 子图用 LlamaIndex 维护索引与检索节点。选型不必「单选一门」;关键是边界清晰:谁管业务事务,谁管模型调用图,谁管数据索引。
6. 小结
- 编排解决的是控制流、状态、恢复与观测,不是替你做 prompt 工程。
- 四大范式:状态图、多 Agent、RAG 管道、通用长事务;外加低代码集成类。
- 选型先看是否有环、是否长事务、主导是协作还是状态机、是否检索为中心,再匹配团队栈与合规。
- 组合架构很常见:长事务运行时 + LLM 图编排 + 检索子系统。
若你已锁定某一类(例如「只要 Temporal 包 LangGraph」),可以再拆一版「接口契约与目录结构」的落地文,避免两层互相泄漏状态。
段末注释:trace 常指分布式追踪中的调用链观测数据(如 OpenTelemetry)。