随着数据爆炸,针对一个项目,我们可以获得许多测量结果,但其中只有一部分对于决策任务有用。尽管机器学习算法(MLA)可以处理大数据,但其性能会随着维度的增加而下降。当属性数量增加时,观察数量也会成比例增加,结果学习模型变得更加复杂。对许多特征进行训练的模型变得强烈依赖于数据,因此导致对未见过的数据的过度拟合和低性能。由于涉及不显着且相似的特征,模型的准确性会降低。降维算法旨在解决维数灾难,其目标是通过降低数据复杂度来提高数据质量。主要分为特征选择(寻找信息量最大的特征并消除信息量较小的特征)和特征提取(通过代数变换将特征组合成更少的新特征)。所以很多时候我们需要关注特征提取算法(FEA,Feature Extraction Algorithms),来更好地处理现实数据集中的问题,例如噪声、复杂性和稀疏性。这就是有限元分析(Finite element method)吸引了研究界更多关注的原因。
特征过多可能出现特征之间具有多重共线性,即特征之间互相具有关联关系,导致解空间不稳定,模型泛化能力弱,数据冗余等问题;过多特征也会妨碍模型学习规律,因为诸如此类的问题,一般来说,如果特征过多,我们都会在前期处理阶段,进行特征降维就是指可以用更少维度的特征替代更高维度的特征,同时保留有用的信息。从而用尽可能少的数据维度来反应尽可能大的信息量,同时提高模型的泛化能力。另一方面,实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此我们必须对数据进行降维,来通过有限的信息损失来极大的降低计算成本。
降维的优势
- 通过减少误导和冗余,来提高机器学习算法的识别精度。
- 通过更少的特征来避免过度拟合,从而减少模型的复杂度,简化模型。
- 更少的特征,对应的计算资源需求减少,同时也可以降低存储空间的需求。
- 更容易数据可视化和解释。
- 通过降维的过程,寻找主要的特征,帮助我们理解数据内部的本质特征。
目前在机器学习的应用过程中,如果输入特征过多,特征降维已经成为模型训练前,数据预处理的标准流程。而随着应用场景的不断丰富,目前已经发展出大量特征提取的算法。
降维算法分类
线性有限元分析算法
基于映射函数的类型分类
- 线性有限元分析将高维空间线性映射到较低的空间,即较低的维度是原始维度的线性组合。比如:奇异值分解 (SVD)、主成分分析 (PCA)、小波变换 (WT)、线性判别分析 (LDA)、独立成分分析 (ICA)、因子分析 (FA) 和非负矩阵因子(NMF)
- 非线性FEA非线性映射高位空间进入低纬空间, 本身由氛围:
- 全局FEA,提供数据店的全局结构的表示。示例包括多为缩放(MDS)、内核PCA(KPCA)和等距映射(ISOMAP)
- 局部有限元分析在流形上产生更好的性能,其中“局部几何接近欧几里德”,但“全局几何可能不是”[19]。示例包括自动编码器、拉普拉斯特征图 (LE)、核费希尔判别分析 (KFDA)、LDA 的线性扩展、局部线性嵌入 (LLE) 和 t 分布随机邻域嵌入 (t-SNE)。
基于数据标签情况分类
- 无监督 FEA 专注于数据本身,没有预先存在的类标签 [20]。大多数 FEA 都是无人监督的。例如 MDS、SVD、PCA、LLE、ISOMAP、t-SNE 和 LE。
- 有监督的 FEA 在从数据中学习时会考虑类标签的信息 [20]。例如 LDA 和 ICA。
基于头型模式
- 基于随机投影的有限元分析通过利用随机矩阵来有效地投影原始数据,其中每列包含一个单位长度,其中该列的每个元素的平方和的平方根为 1,同时保留实际相对距离数据之间的欧几里得空间。 [21,22]。示例包括 PCA、LDA 和 SVD。
- 基于流形 大多数基于流形的有限元分析都是非线性的、无监督的 [23] 和基于邻域图的 [4]。
具体FEA算法
主成分分析
主成分分析 (PCA, Principal component analysis )
主成分分析(PCA)是一种线性、无监督的变换算法,它通过确定数据的最大方差来产生新的特征,称为主成分(PC, Principal Components )。 PCA 将高维数据集投影到一个新的子空间,其中正交轴或 PC 被视为最大数据方差的方向 。在转换过程中,第一个 PC 的方差最高,后续 PC 的方差逐渐减小。
优点:它是非迭代的,因此耗时较少,可以很好地减少过度拟合,并且还可以用作去噪和数据压缩技术
缺点:仅限于线性投影,因此不能很好地处理非线性数据;在应用PCA之前必须进行数据标准化,否则由于方向对特征尺度非常敏感,将无法找到最佳PC(方差的大,可能是度量单位导致的);如果不仔细选择PC,则可能会发生信息主程序的排序错误导致重要信息丢失。
内核主成分分析 (KPCA,Kernel Principal component analysis )
PCA 在非线性数据上表现不佳,因为生成的子空间不是最优的。因此,内核 PCA (KPCA) 变得很方便。它使用$ K(x_a,x_b)=\emptyset$(X_a)^T *\emptyset$(X_b)$中所示的“内核技巧”K将数据投影到更高的特征空间,以便数据可以线性分离。
简单来讲,就是在PCA分析前,通过一个核函数对数据进行处理。常见的核函数有:Linear、Gaussian kernel、Sigmoid、Polynomial 等。
线性判别分析 (LDA, Linear Discriminant Analysis )
大多数时候,线性判别分析 (LDA) 被定义为线性、有监督的有限元分析。然而,一些作者指出 LDA 也可以作为线性分类器。 LDA 确定了一个新的特征空间来投影数据,其目标是最大化类的可分离性。从数据集的 d 个独立特征中,它提取 k 个新的独立特征,这些特征将类别(依赖特征)分开最多。LDA和PCA的区别如下图: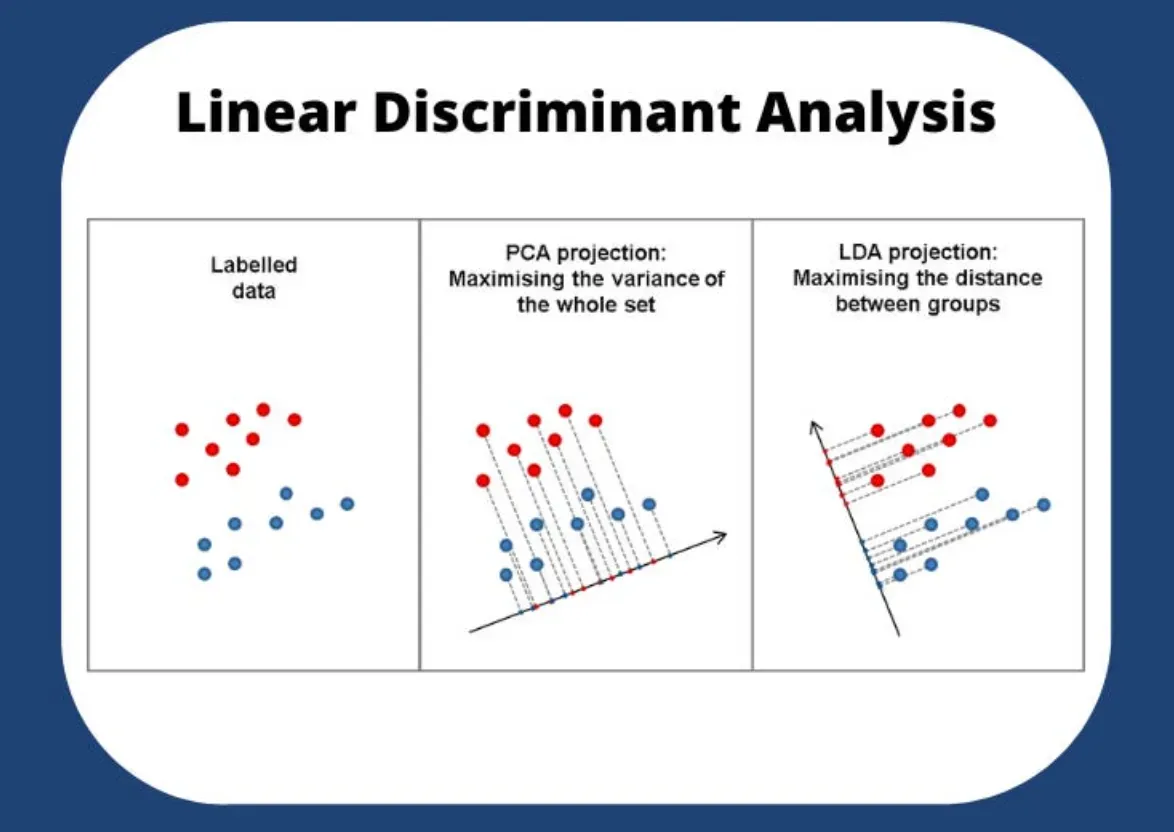
PCA是在寻找所有数据方差表现最大的方向,LDA是寻找各个类之间差距最大的方向。其次就是LDA进行分析后,特征只有 总类别数-1 的维度,PCA本身就没有这个限制。
多维度缩放 (MDS, Multi-dimensional scaling )
是一种非线性、无监督的有限元分析,重点关注多维空间中数据之间的关系(相似性或相异性)。MDS 有两种主要方法:(1).度量MDS(经典)和非度量MDS。在这项工作中,我们介绍了广泛采用的经典 MDS,也称为主坐标分析(Principal Coordinate Analysis)。如算法4所示,MDS一般不关心数据;相反,它更关注数据对之间的成对差异。
MDS 通过计算相异/距离矩阵来定位较低维度的数据点,使得相似的数据在一起,不太相似的数据相距很远[37]。根据距离矩阵 d,MDS 找到使 d 和 d 之间的相似度最大化的输出 Y,其中 d=
奇异值分解 (SVD, Singular Value Decomposition )
提供了表示为任意维数矩阵的数据集的精确说明。然而,我们选择的维度(分量)数量越少,SVD 的说明就越不精确。
局部线性嵌入 (LLE, Locally linear embedding)
是一种非线性、无监督的提取过程,它通过假设数据位于嵌入高特征空间的平滑非线性流形上来生成低维全局坐标
等距映射 (Isometric mapping)
经典缩放是一种公认的计算数据差异的方法,旨在保留数据点的成对距离(欧几里德距离),但不考虑相邻数据的分布。
独立成分分析 (ICA, Independent Component Analysis )
因子分析 (FA, Factor Analysis )
小波变换 (WT, Wavelet Transformation )
总结和比较
EFA方法的比较
| 方法 | 目标 | 监督 | 线性 | 数据特征 | 迭代 | 拓扑结构 |
|---|---|---|---|---|---|---|
| PCA | 最大化方差 | 无监督 | 线性 | 数据有偏差 | 非迭代 | 随机投影 |
| KPCA | 线性分离数据(基于最大方差) | 无监督 | 非线性 | 非线性数据表现更好 | 非迭代 | 流形 |
| LDA | 最大化类分离 | 简单 | 线性 | 连续分布数据表现更好 | 非迭代 | 随机投影 |
| MDS | 保存数据对的欧几里得和距离 | 无监督 | 非线性 | 关系型数据表现更好 | 迭代 | 流形 |
| SVD | 最小化重建错误 | 无监督 | 线性 | 处理稀疏数据 | 迭代 | 随即投影 |
| LLE | 保存局部特征 | 无监督 | 非线性 | 处理稀疏非线性数据 | 迭代 | 流形 |
| 等距映射 | 保存数据对的距离 | 无监督 | 非线性 | 处理稀疏有噪音的数据 | 非迭代 | 流形 |
| LE | 保存局部距离 | 无监督 | 非线性 | 处理噪音数据 | 非迭代 | 流形 |
| ICA | 最大化独立统计 | 监督 | 线性 | 处理higher order statistics | 迭代 | 随机投影 |
| t-SNE | 保存局部结构 | 无监督 | 非线性 | 数字量化数据表现更好 | 迭代 | 流形 |
reference:
[1]. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE) pdf