Normalization 层主要解决的问题是希望输入数据能大致分布在相同的空间内,从而让训练更好更快的收敛。 最先提出的 Batch normalization 层对于深度网络的收敛起到了很大的促进作用,于是后续又有多种normalization层提出,这里总结下normlization的相关知识。
深度网络中,对数据多次线性和非线性变换,所以可能刚开始处于相同空间内的样本,比如图像数据,经过若干层后的输出差距非常大,那么这些差距较大的数据可能处于不同的数据空间,继而导致更高层需要不断的更新参数去适应每一种分布,使得训练比较难收敛。
Google称这种现象为Internal Covariate Shift, 即网络中间层的输入数据空间分布发生变化, 这种变化带来的问题:
- 高层的参数需要较大的迭代更新以适应新的数据分布, 使得模型收敛较慢
- 每层的参数更新对其它层参数影响较大,而且这种影响是累积的
- 可能导致低层输入较小变化不会反映到最后输出中,导致上层的激活函数处于饱和区,学习过早停止。
而BN层的提出是希望将每一层的输出通过归一化的形式缩放移动到相同的空间分布中,从而使得模型更快的收敛。
主流的Normalization方法
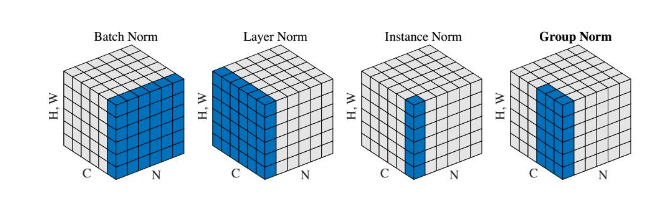
假设上一层的输出数据大小是 $ N×C×H×W $, 那么
- Batch Norm: 在batch方向上做归一化,计算的是 $NHW$ 的归一化;
- Layer Norm: 在channel方向做归一化,即每个样本输出元素做归一化处理, 算的是 $CHW$ 的归一化;
- Instance Norm: 在每一层feature map上归一化, 即每个样本的每一层的 $ H∗W $ 元素进行归一化;
- GroupNorm: 这个是Layer Norm的更泛化的方法,将通道划分成多个group, 每个group内进行单独的LayerNorm, 当group数目等于channel数目时等价于Instance norm, 当group=1时就是Layer Norm。
对应的不同使用场景
- BN适用于batchsize较大, 且每个batch数据分布比较接近的场景。 BN采用的是平均滑动均值和方差。
- LN针对于单个样本进行归一化,避免了BN中batch分布于整体分布差距较大的情形, 适用于小batchsize的场景、动态网络场景和RNN, NLP领域。 LN不需要保存动态的均值和方差,节省空间。
- IN 规范化在GAN和style transfer任务中要由于BN, IN和LN一样操作目标是单个样本,另外上面我们也说到LN是所有的通道规范化到相同空间,降低了模型表征能力, 而IN不同,他和BN一样对每一个通道单独操作。
- GN相当于与对IN和LN进行了泛化,是对BN的改善。能够处理BN针对于小batch表现不好的情形。
BN归一化是对每一层的featuremap操作的, 而LN是对所有层的featmaps操作的,LN会让所有的通道都处于一个分布空间,BN不同通道可以处于不同空间。 BN相对于LN而言有更强的表征能力。
BN的计算是要受其他样本影响的,由于每个batch的均值和标准差不稳定,对于单个数据而言,相对于是引入了噪声,但在分类这种问题上,结果和数据的整体分布有关系,因此需要通过BN获得数据的整体分布。而instance norm的信息都是来自于自身的图片,相当于对全局信息做了一次整合和调整,在图像转换这种问题上,BN获得的整体信息不会带来任何收益,带来的噪声反而会弱化实例之间的独立性:这类生成式方法,每张图片自己的风格比较独立不应该与batch中其他的样本产生太大联系