← 系列入口:RL-00.系列概述
强化学习(Reinforcement Learning,RL)研究的核心问题可以浓缩成一句话:智能体在不确定环境中,通过反复交互,学会做出能最大化长期回报的序贯决策。本文建立 RL 的「一屏心智模型」,为后续 MDP 公式与算法篇打底。
段末注释:强化学习(Reinforcement Learning,RL)指通过环境反馈信号学习决策策略的机器学习范式;后文沿用 RL。
一、先立骨架:RL 在你脑子里该长什么样
第一句:RL 不是「给定输入—标签对」,而是「行动—观察—反馈」的循环。
监督学习里,每个样本通常带有正确答案;RL 里,智能体(Agent)每走一步,环境(Environment)只给标量奖励(Reward)和新状态,很少直接告诉「这一步对不对」。学习信号来自长期累积,而非单步标签。
第二句:学习靠试错,回报往往延迟。
下棋要到终局才知道胜负;机器人练走路要很多步才体现「没摔倒」。因此 RL 必须处理探索(试新路)与利用(走已知好路)的权衡,以及信用分配(哪一步该为最终结果负责)。
第三句:形式化工具是 MDP,工程落地是「环境 API + 训练循环」。
数学上用马尔可夫决策过程(Markov Decision Process,MDP)描述问题;代码上常见 reset / step 接口与策略/价值网络的更新循环。细节见 RL-02.原理与数学基础 与 RL-04.实现框架与实践。
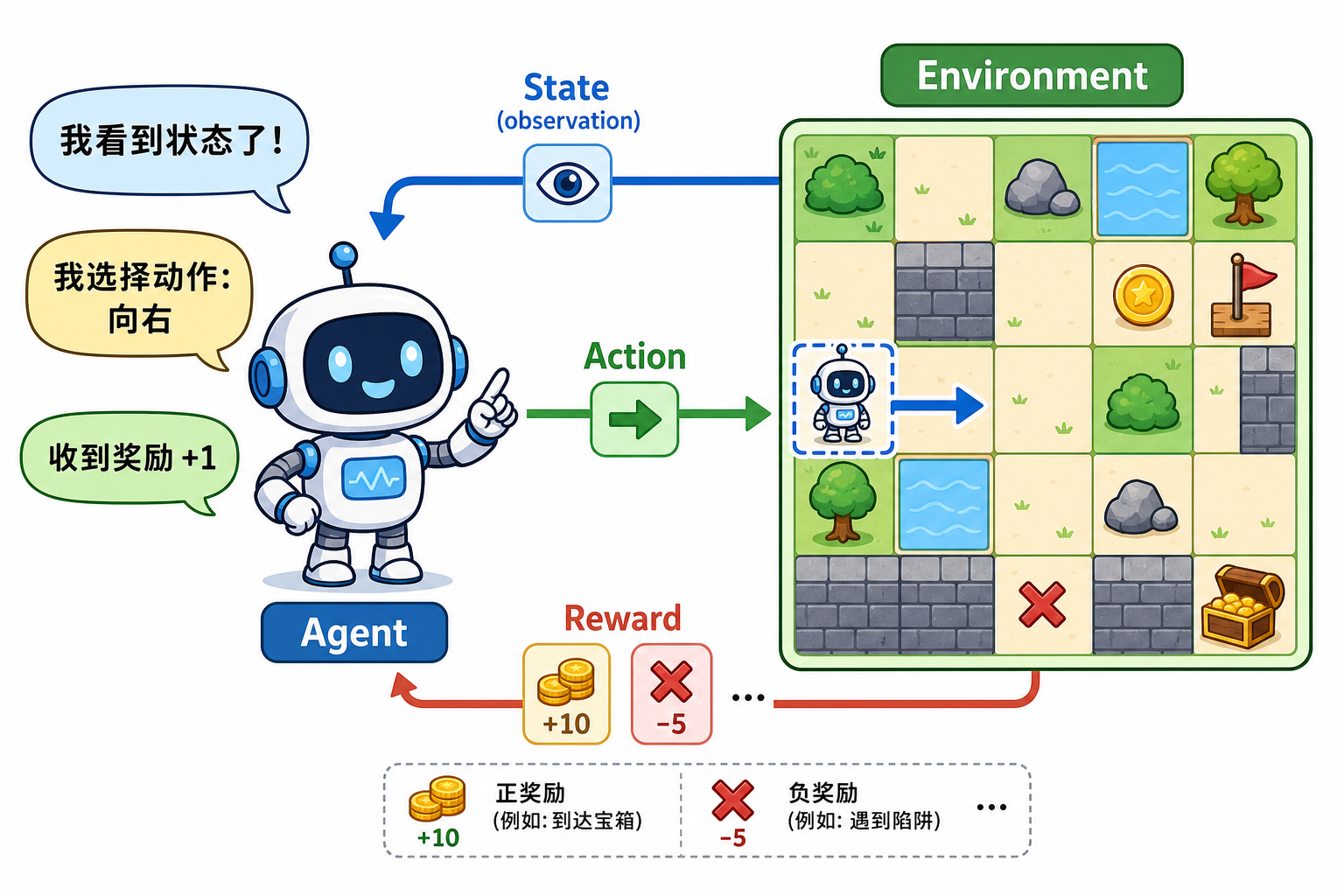
二、基本元素:Agent 与 Environment
| 元素 | 含义 | 直觉类比 |
|---|---|---|
| Agent(智能体) | 做决策的主体 | 棋手、机器人控制器、推荐策略 |
| Environment(环境) | Agent 之外、对其行动给出反馈的系统 | 棋盘规则、物理世界、用户行为 |
| State $s$(状态) | 对当前局势的描述 | 棋谱局面、传感器读数 |
| Observation $o$(观测) | 状态的部分、带噪声的视图 | 摄像头图像、局部地图 |
| Action $a$(动作) | Agent 可执行的操作 | 落子、油门/转向、点击商品 |
| Reward $r$(奖励) | 环境给的标量反馈 | +1 进球、-100 撞车、0 普通步 |
一次交互可记为:在状态 $s_t$ 下选动作 $a_t$,环境返回奖励 $r_{t+1}$ 并转移到 $s_{t+1}$。多步组成 episode(回合) 或 trajectory(轨迹) $\tau = (s_0,a_0,r_1,s_1,\ldots)$。
段末注释:马尔可夫决策过程(Markov Decision Process,MDP)用 $(S,A,P,R,\gamma)$ 形式化上述交互;详见 RL-02。
三、RL 的两个鲜明特点
3.1 试错学习(Trial-and-Error)
没有老师逐步标注「这一步最优」;Agent 通过尝试不同动作、观察回报,逐步改进策略(Policy)$\pi(a|s)$——在状态 $s$ 下选动作 $a$ 的规则(可确定或随机)。
3.2 延迟回报(Delayed Reward)
中间步骤的奖励可能全为 0,只有终局才有大正/负奖励。因此需要折扣回报(Discounted Return)把未来奖励汇总到当前:
$$
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}
$$
其中 $\gamma \in [0,1]$ 为折扣因子(Discount Factor):越远的奖励权重越小,体现「远水解不了近渴」。
四、与监督学习、无监督学习的对比
| 范式 | 数据形态 | 目标 | 典型算法 |
|---|---|---|---|
| 监督学习 | $(x, y)$ 成对 | 拟合输入到标签的映射 | 线性回归、CNN 分类 |
| 无监督学习 | 仅 $x$ | 发现结构/分布 | 聚类、VAE |
| 强化学习 | 交互序列 $(s,a,r,\ldots)$ | 最大化期望累积回报 | Q-Learning、PPO |
RL 也常借用深度学习做函数逼近(Deep RL):用神经网络表示策略或价值函数,此时与监督学习的交叉点是「用梯度更新网络」,但标签来自 Bootstrapping 或策略梯度,而非静态数据集。
五、动作空间与部分可观测
- 离散动作空间:有限个动作(上下左右、买/卖/持有)。表格型方法(Q 表)常在此起步。
- 连续动作空间:实向量(关节力矩、油门开度)。需策略梯度、DDPG、SAC 等,见 RL-03.算法分类与选型。
当 Agent 看不到完整状态时,问题升级为部分可观测 MDP(Partially Observable MDP,POMDP):需用历史观测或 RNN/Transformer 维护信念状态。入门阶段可先按完全可观测 MDP 理解,再扩展。
段末注释:部分可观测 MDP(Partially Observable MDP,POMDP)指 Agent 只能获得状态的噪声或局部观测;后文沿用 POMDP。
六、典型应用场景
| 领域 | 问题形态 | 状态/动作直觉 |
|---|---|---|
| 博弈 | 围棋、星际、MOBA | 盘面/屏幕 → 落子或按键 |
| 机器人 | 行走、抓取、导航 | 传感器 → 电机指令 |
| 推荐与广告 | 序列推荐、出价 | 用户上下文 → 展示/出价 |
| 资源调度 | 集群任务、网络路由 | 队列/负载 → 调度决策 |
| 自动驾驶 | 轨迹规划、控制 | 感知融合 → 转向/加速 |
应用落地路径见 RL-07.应用实战。
七、核心术语速查
| 符号/术语 | 含义 |
|---|---|
| $\pi$ | 策略:$$a \sim \pi(\cdot|s)$$ |
| $V^\pi(s)$ | 在策略 $\pi$ 下,从 $s$ 出发的期望回报 |
| $Q^\pi(s,a)$ | 在 $s$ 先执行 $a$ 再按 $\pi$ 行动的期望回报 |
| $\pi^*$ | 最优策略 |
| On-Policy / Off-Policy | 更新用的数据是否必须来自当前策略 |
完整约定见二级篇 RL-01-01-术语与符号约定(含上标 $\pi$ / $*$ 的含义)。
八、本模块二级文档(已发布)
| 文档 | 内容 |
|---|---|
| RL-01-01-术语与符号约定 | 全系列 $\pi$、$V$、$Q$、$\gamma$、$\pi^$、$Q^$ 等统一 |
| (交叉) | MachineLearn:强化学习概述 |
九、阅读顺序
- 本文 — 建立 Agent / Environment / Reward 心智模型
- RL-01-01-术语与符号约定 — 符号速查(可选,遇符号疑问时查阅)
- RL-02.原理与数学基础 — MDP 与 Bellman
- RL-03.算法分类与选型 — 算法地图
十、小结
- RL = 序贯决策 + 环境反馈 + 长期回报最大化。
- 五大元素:Agent、Environment、State、Action、Reward。
- 两大难点:探索—利用、延迟回报与信用分配。
- 下一篇:用 MDP 把「交互故事」写成可计算的数学对象。