← 上级:RL-03.算法分类与选型 · 原理:RL-02.原理与数学基础 · TD 理论:RL-03-05-算法-时序差分 · 数据结构:RL-05.专属数据结构
Q-Learning 是最经典的 Off-Policy、基于价值的表格型 RL 算法:不显式维护策略,而是直接估计最优动作价值 $Q^*(s,a)$,再用贪心或 $\varepsilon$-greedy 导出行为。
段末注释:Q-Learning 为 Watkins 提出的离策略时序差分算法,直接逼近 Bellman 最优方程;后文沿用该名称。
一、核心思想
Bellman 最优方程(动作价值形式):
$$
Q^(s,a) = \mathbb{E}\left[ R + \gamma \max_{a’} Q^(S’, a’) \mid S=s, A=a \right]
$$
Q-Learning 用采样一步转移 $(s,a,r,s’)$ 构造 TD 目标,朝该目标移动当前估计:
$$
Q(s,a) \leftarrow Q(s,a) + \alpha \left[ \underbrace{r + \gamma \max_{a’} Q(s’,a’)}_{\text{TD 目标}} - Q(s,a) \right]
$$
其中 $\alpha$ 为学习率,$\delta = r + \gamma \max_{a’} Q(s’,a’) - Q(s,a)$ 为 TD 误差。
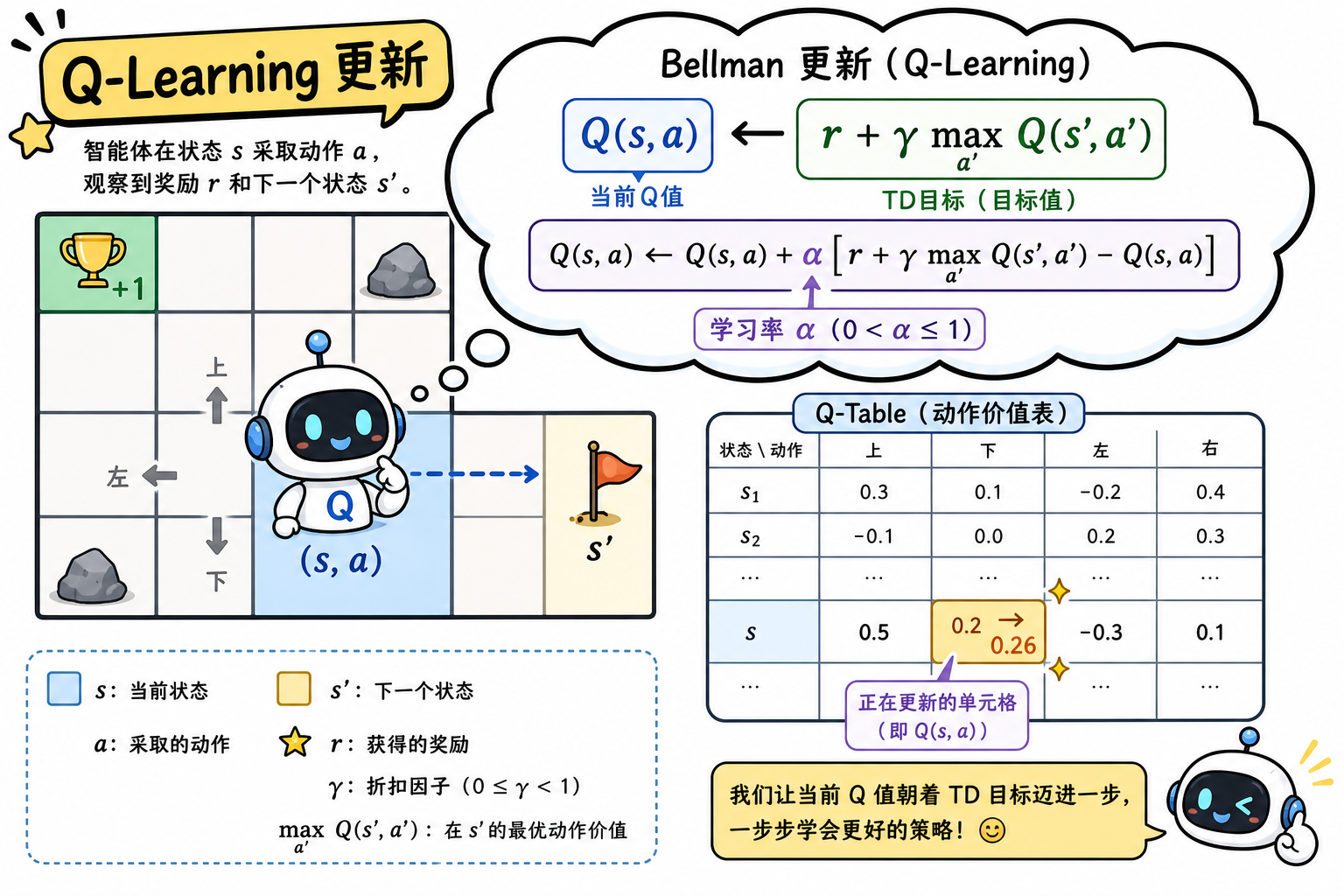
Off-Policy 体现:TD 目标中的 $\max_{a’} Q(s’,a’)$ 对应最优下一动作,与实际执行的动作(可能来自 $\varepsilon$-greedy 探索)无关。
二、算法流程
- 初始化 $Q(s,a)$(常全零或乐观初值)。
- 对每个 episode:
- $s \leftarrow \text{env.reset}()$
- 重复直到终止:
- 用 $\varepsilon$-greedy 从 $Q(s,\cdot)$ 选 $a$
- 执行 $a$,得 $r, s’$
- 按上式更新 $Q(s,a)$
- $s \leftarrow s’$
- 可选:每步或每 episode 衰减 $\varepsilon$。
2.1 $\varepsilon$-greedy 行为策略
$$
a = \begin{cases}
\text{random action} & \text{以概率 } \varepsilon \
\arg\max_a Q(s,a) & \text{以概率 } 1-\varepsilon
\end{cases}
$$
行为策略(探索)与学习目标(最优 Q)分离,这是 Off-Policy 的典型模式。
三、伪代码
1 | Q = np.zeros((n_states, n_actions)) |
数据结构详见 RL-05 Q-Table;MachineLearn 目录另有 迷宫算例。
四、收敛性(直觉)
在表格、有限 MDP 下,若:
- 所有 $(s,a)$ 被无限次访问
- 学习率满足 Robbins-Monro 条件($\sum \alpha = \infty$,$\sum \alpha^2 < \infty$)
则 Q-Learning 收敛到 $Q^*$(Watkins & Dayan, 1992)。实践中常用固定小 $\alpha$ 或分段衰减。
五、超参数
| 超参 | 典型值 | 说明 |
|---|---|---|
| $\alpha$ | 0.1 ~ 0.5 | 过大震荡,过小慢 |
| $\gamma$ | 0.9 ~ 0.99 | 长期任务取大 |
| $\varepsilon$ | 1.0 → 0.01 | 探索衰减 |
| episode 数 | 依环境 | 需覆盖状态空间 |
六、与 SARSA 对比
| Q-Learning | SARSA | |
|---|---|---|
| 类型 | Off-Policy | On-Policy |
| TD 目标 | $r + \gamma \max_{a’} Q(s’,a’)$ | $r + \gamma Q(s’, a’)$,$a’$ 为实际执行 |
| 风险偏好 | 更「乐观」(学最优路径) | 更保守(考虑探索带来的风险) |
七、局限与延伸
| 局限 | 延伸 |
|---|---|
| 仅适用离散、小 $ | S |
| 无连续动作 | 策略梯度 / SAC |
| 表格不泛化 | 特征 + 线性 Q 或神经网络 |
八、小结
- Q-Learning = Bellman 最优方程 + 一步 TD + Off-Policy max。
- 实现核心:Q 表 + $\varepsilon$-greedy + TD 更新。
- 下一篇:SARSA(On-Policy 对照)。