← 系列入口:RL-00.系列概述 · 上一篇:RL-02.原理与数学基础
RL-02 给出了 Bellman 方程与价值函数;不同算法本质上是对「如何采样、更新谁($V/Q/\pi$)、是否需要环境模型」的不同选择。本文提供算法地图与选型轴,便于在写代码前快速定位方法族。
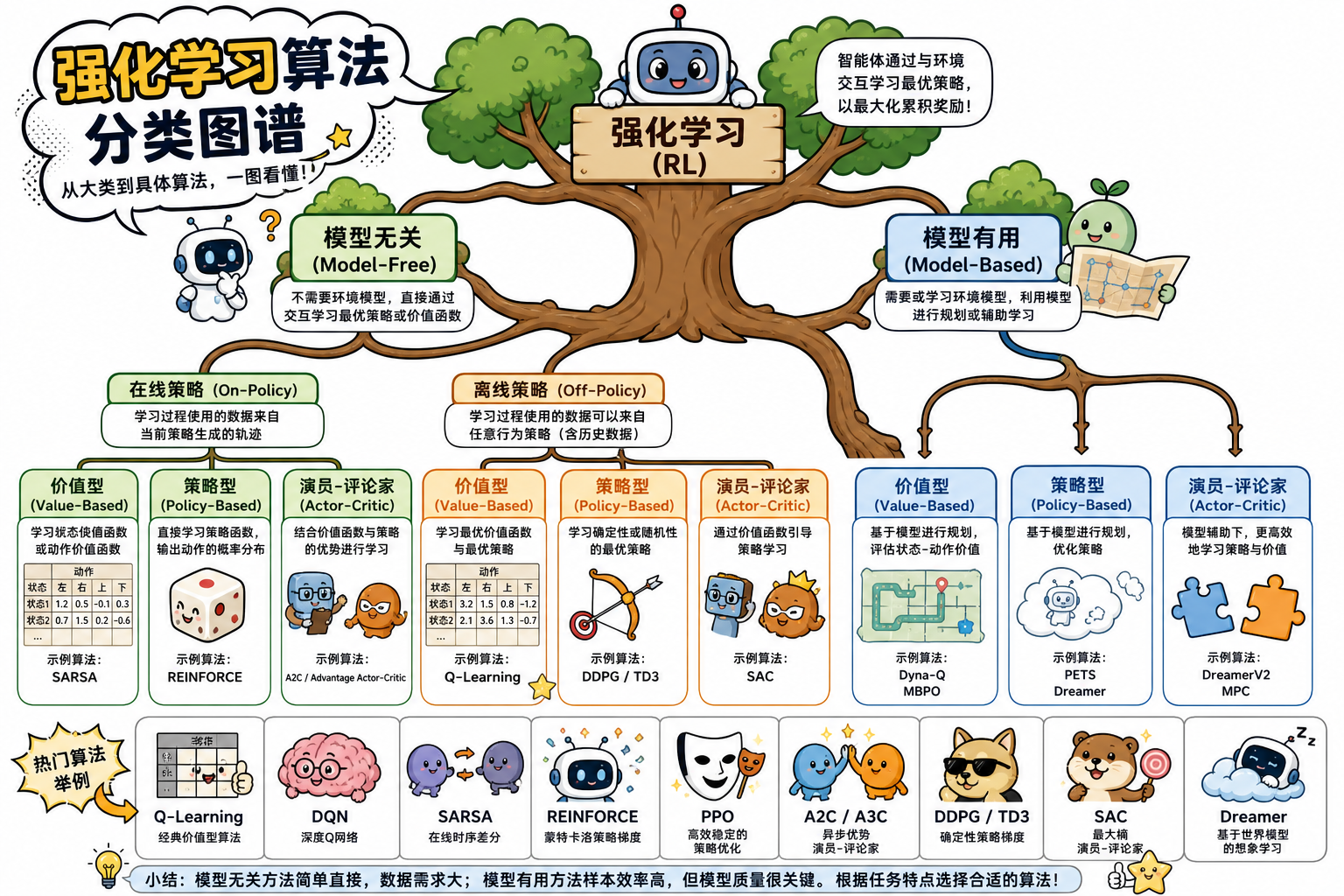
一、三条分类轴
1.1 是否学习环境模型
| 类型 | 思路 | 代表 |
|---|---|---|
| Model-Free(无模型) | 不估计 $P(s’ | s,a)$,直接学价值或策略 |
| Model-Based(有模型) | 学 $\hat{P},\hat{R}$ 或在模型中规划 | Dyna-Q、MCTS+学习、World Models |
绝大多数深度 RL 工程实践从 Model-Free 起步;模型方法样本效率可能更高,但模型误差会传播。
1.2 On-Policy vs Off-Policy
| 类型 | 数据要求 | 代表 |
|---|---|---|
| On-Policy(在策略) | 更新用的轨迹必须来自当前策略 | SARSA、A2C、PPO |
| Off-Policy(离策略) | 可用旧策略或行为策略的数据 | Q-Learning、DQN、DDPG、SAC |
Off-Policy 常配合经验回放(见 RL-05.专属数据结构),样本利用更充分,但稳定性需额外设计(目标网络、Double Q 等)。
1.3 优化对象:Value / Policy / Actor-Critic
| 类型 | 输出/优化 | 动作空间 | 代表 |
|---|---|---|---|
| Value-Based(基于价值) | 学 $Q(s,a)$,贪心得动作 | 主要为离散 | Q-Learning、DQN |
| Policy-Based(基于策略) | 直接参数化 $\pi_\theta(a | s)$ | 离散/连续 |
| Actor-Critic | Actor 出动作,Critic 估 $V$ 或 $Q$ | 离散/连续 | A2C、DDPG、SAC |
Actor-Critic 可看作「策略梯度 + 价值基线」的结合,是当前连续控制与大动作空间的主流。
二、算法谱系:从表格到深度
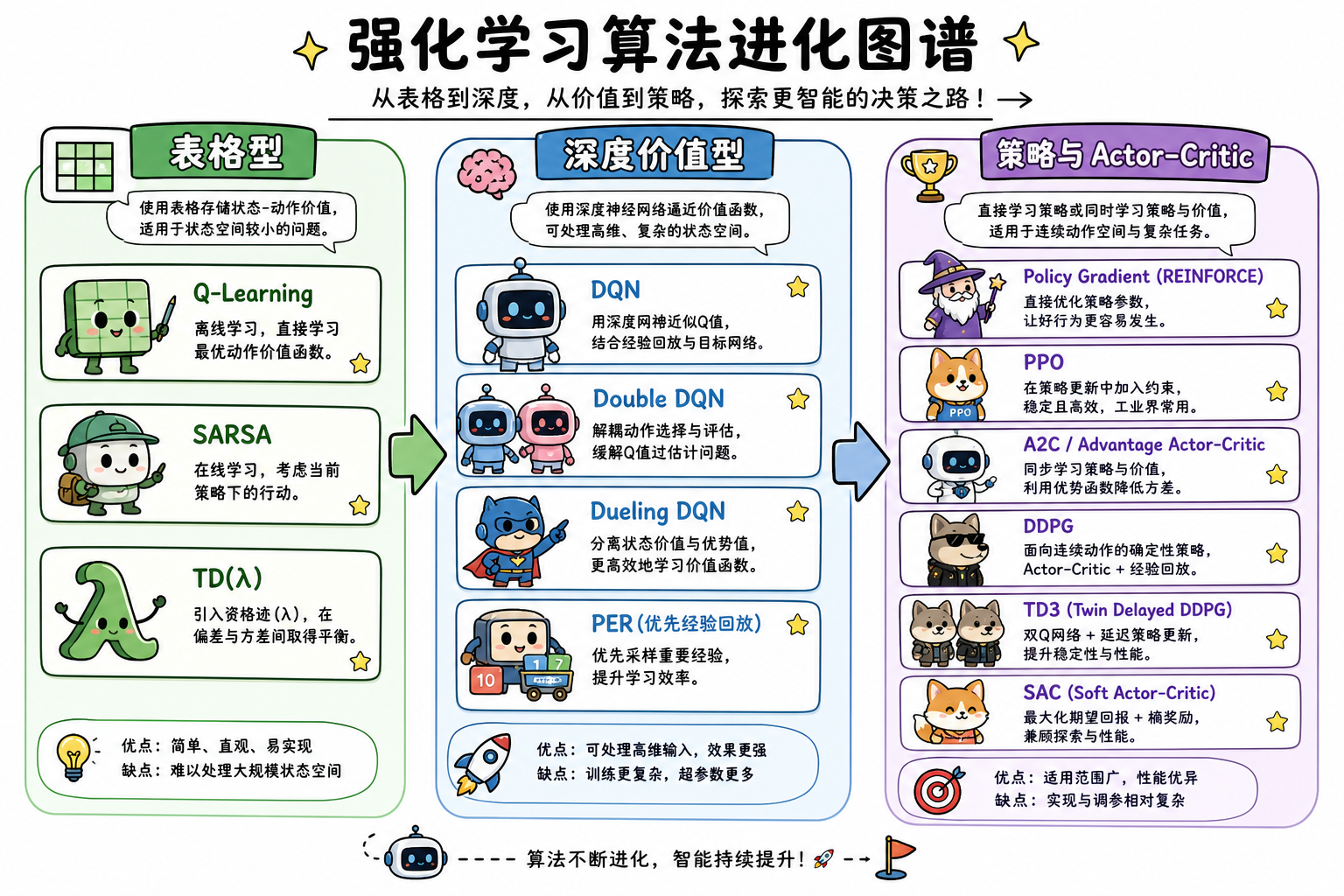
2.1 规划与表格型(入门必学)
| 算法 | 需模型 | 说明 |
|---|---|---|
| 动态规划 | 已知 $P,R$ | 策略/价值迭代,无采样 |
| Q-Learning | 否 | Off-Policy TD 控制 |
| SARSA | 否 | On-Policy TD 控制 |
| 蒙特卡洛 | 否 | 完整 $G_t$ 回报 |
| 时序差分 TD | 否 | Bootstrap、TD($\lambda$) |
| Dyna-Q | 在线学 | Q-Learning + 模拟规划 |
已有详解:动态规划、Q-Learning;MachineLearn 目录另有 迷宫算例。
2.2 深度价值型
| 算法 | 关键机制 |
|---|---|
| DQN | 神经网络逼近 $Q$ + 经验回放 + 目标网络 |
| Double DQN | 缓解 Q 过估计 |
| Dueling DQN | 分离 $V(s)$ 与优势 $A(s,a)$ |
| Rainbow | 多种改进组合 |
局限:连续动作上 $\max_{a’} Q(s’,a’)$ 不易直接做。
2.3 策略梯度与 PPO
REINFORCE:$\nabla_\theta J \approx \mathbb{E}[\nabla_\theta \log \pi_\theta(a|s) \cdot G_t]$,方差大。
PPO(Proximal Policy Optimization,PPO):限制策略更新幅度(clip surrogate),稳定且实现相对简单,离散/连续通用,常作默认基线。
段末注释:近端策略优化(Proximal Policy Optimization,PPO)通过裁剪目标函数限制策略更新步长;后文沿用 PPO。
2.4 连续控制:DDPG / TD3 / SAC
| 算法 | 特点 |
|---|---|
| DDPG | 确定性 Actor + Q Critic,Off-Policy |
| TD3 | 双 Critic、延迟更新、目标策略平滑 |
| SAC | 最大熵 RL,随机策略,探索更稳 |
三、横向对比表
| 算法 | Model | On/Off | 动作 | 样本效率 | 实现难度 | 典型场景 |
|---|---|---|---|---|---|---|
| Q-Learning | Free | Off | 离散 | 中(小空间) | 低 | 教学、小迷宫 |
| Dyna-Q | Based | Off | 离散 | 较高(表格) | 低 | 小 MDP + 模型 |
| DQN | Free | Off | 离散 | 中 | 中 | Atari、离散控制 |
| PPO | Free | On | 离散/连续 | 中 | 中 | 通用默认 |
| SAC | Free | Off | 连续 | 较高 | 中高 | 机器人仿真 |
| TD3 | Free | Off | 连续 | 较高 | 中高 | MuJoCo 控制 |
四、怎么选:决策流程
状态空间大小
- 小且离散 → Q-Learning / SARSA
- 大或高维(图像)→ DQN 或 Policy / Actor-Critic
动作空间
- 离散 → DQN、PPO
- 连续 → PPO、SAC、TD3
样本成本
- 仿真便宜 → PPO 简单可靠
- 需高样本效率 → SAC、Off-Policy + 大 Replay
稳定性优先
- 首选 PPO(调参相对友好)
- 避免一上来就上复杂 Rainbow + 多技巧叠加
工程生态
- 快速实验:RL-06.评估环境与工具链 中的 Stable-Baselines3
五、二级算法文档(已发布)
| 分类 | 文档 | 说明 |
|---|---|---|
| 规划 | 动态规划 | 策略/价值迭代(已知 $P,R$) |
| 表格 TD | Q-Learning | Off-Policy TD、Q 表 |
| SARSA | On-Policy TD | |
| 蒙特卡洛 | MC 预测与控制 | |
| 时序差分 | TD(0)、n-step、TD($\lambda$) | |
| 深度价值 | DQN | Replay、目标网络 |
| DQN 变体 | Double、Dueling、PER、Rainbow | |
| 策略 | Policy Gradient | REINFORCE、基线 |
| Actor-Critic | Actor-Critic | A2C/A3C |
| TRPO | KL 信任域 | |
| PPO | Clip、GAE | |
| DDPG / TD3 / SAC | 连续控制 | |
| Model-Based | Dyna-Q | 表格模型 + 模拟 Q |
| 选读 | Model-Based 简介 | MCTS、Dreamer、MuZero |
| 扩展 | 多智能体 RL | MADDPG、QMIX、MAPPO |
| 模仿与逆 RL | BC、DAgger、GAIL | |
| 进化策略 | ES、CMA-ES、PBT |
建议阅读顺序
- 动态规划 → Q-Learning → SARSA
- 蒙特卡洛 → 时序差分
- DQN → DQN 变体
- Policy Gradient → Actor-Critic → TRPO → PPO
- DDPG / TD3 / SAC
- Dyna-Q → Model-Based 简介
- 多智能体 RL · 模仿与逆 RL · 进化策略
八、主流算法覆盖与待扩展
本系列 RL-03 二级篇 已覆盖从表格到深度的主干算法链(共 17 篇)。下表列出尚未单独成篇、但在工业界/研究中仍常见的主流方向,便于按需延伸阅读。
8.1 已覆盖(本目录)
| 类别 | 已收录 |
|---|---|
| 规划 / 表格 | DP、MC、TD、Q-Learning、SARSA、Dyna-Q |
| 深度价值 | DQN、Double/Dueling/PER/Rainbow |
| 策略 / On-Policy | REINFORCE、A2C/A3C、TRPO、PPO |
| 连续 Off-Policy | DDPG、TD3、SAC |
| Model-Based 概览 | Dyna-Q、MCTS、Dreamer、MuZero(简介) |
| 多智能体 | MADDPG、QMIX、MAPPO/IPPO(RL-03-15) |
| 模仿 / 逆 RL | BC、DAgger、GAIL、MaxEnt IRL(RL-03-16) |
| 进化策略 | OpenAI ES、CMA-ES、PBT(RL-03-17) |
| 探索 / Bandit | $\varepsilon$-greedy、UCB(RL-02-03)、Contextual Bandit(RL-07) |
8.2 尚未单独成篇的主流算法
| 类别 | 代表算法 | 典型场景 | 与本系列关系 |
|---|---|---|---|
| 离线 RL | CQL、BCQ、IQL、AWAC | 日志数据、不能在线探索 | 推荐/广告;与 Bandit 实战 衔接 |
| 分布式采样 | IMPALA、R2D2、SEED RL | 大规模 Atari、低延迟 | A3C 已在 Actor-Critic 篇提及 |
| 目标条件 / 稀疏奖励 | HER、Hindsight Policy | 机器人抓取、难探索 | 与奖励设计相关 |
| 层次 RL | Options、HIRO、HAC | 长 horizon 任务分解 | — |
| 探索增强 | RND、Count-based、Go-Explore | 稀疏奖励、硬探索 | 与 RL-02-03 探索篇互补 |
| 分布 RL | C51、QR-DQN、IQN | 风险敏感、稳定 Q | Rainbow 篇已部分覆盖 |
| 序列建模 RL | Decision Transformer、Q-Transformer | 离线数据、无 Bootstrapping | 离线 RL 新范式 |
| 元 RL | MAML-RL、PEARL、RL² | 快速适应新任务 | — |
| 安全 RL | CPO、RCPO、约束 MDP | 机器人、金融 | 与 TRPO/PPO 约束相关 |
8.3 选型补充
| 你的问题 | 可关注 |
|---|---|
| 只有历史日志、不能上线试 | 离线 RL(CQL / IQL) |
| 有专家轨迹、奖励难设计 | 模仿与逆 RL(BC → GAIL) |
| 多机/博弈 | 多智能体 RL(MAPPO / QMIX) |
| 不可微仿真、大规模 CPU | 进化策略 |
| 样本极贵 + 可信仿真 | Model-Based(Dreamer / MBPO),见 RL-03-14 |
| 工程默认、快速验证 | PPO / SAC(已覆盖) |
九、阅读顺序
- 原理基础:RL-02.原理与数学基础
- 实现训练循环:RL-04.实现框架与实践
- 数据结构支撑:RL-05.专属数据结构
- 落地案例:RL-07.应用实战
十、小结
- 算法选型看三轴:有无模型、On/Off-Policy、Value/Policy/Critic。
- 学习路径:DP → Q-Learning → DQN → PPO/SAC 覆盖大部分需求;Dyna-Q 理解 Model-Based 入门。
- 第八节列出尚未成篇的方向(离线 RL、元 RL、层次 RL 等)。
- 扩展篇:多智能体、模仿/逆 RL、进化策略见 RL-03-15~17。
- 下一篇:把这些算法放进统一的代码训练循环与工程框架。