← 系列入口:RL-00.系列概述 · 相关:RL-04.实现框架与实践
算法与代码就绪后,需要可对比的环境与可复现的指标。本文梳理 RL 实验的「度量衡」:环境 API、基准任务、工具链与记录规范。
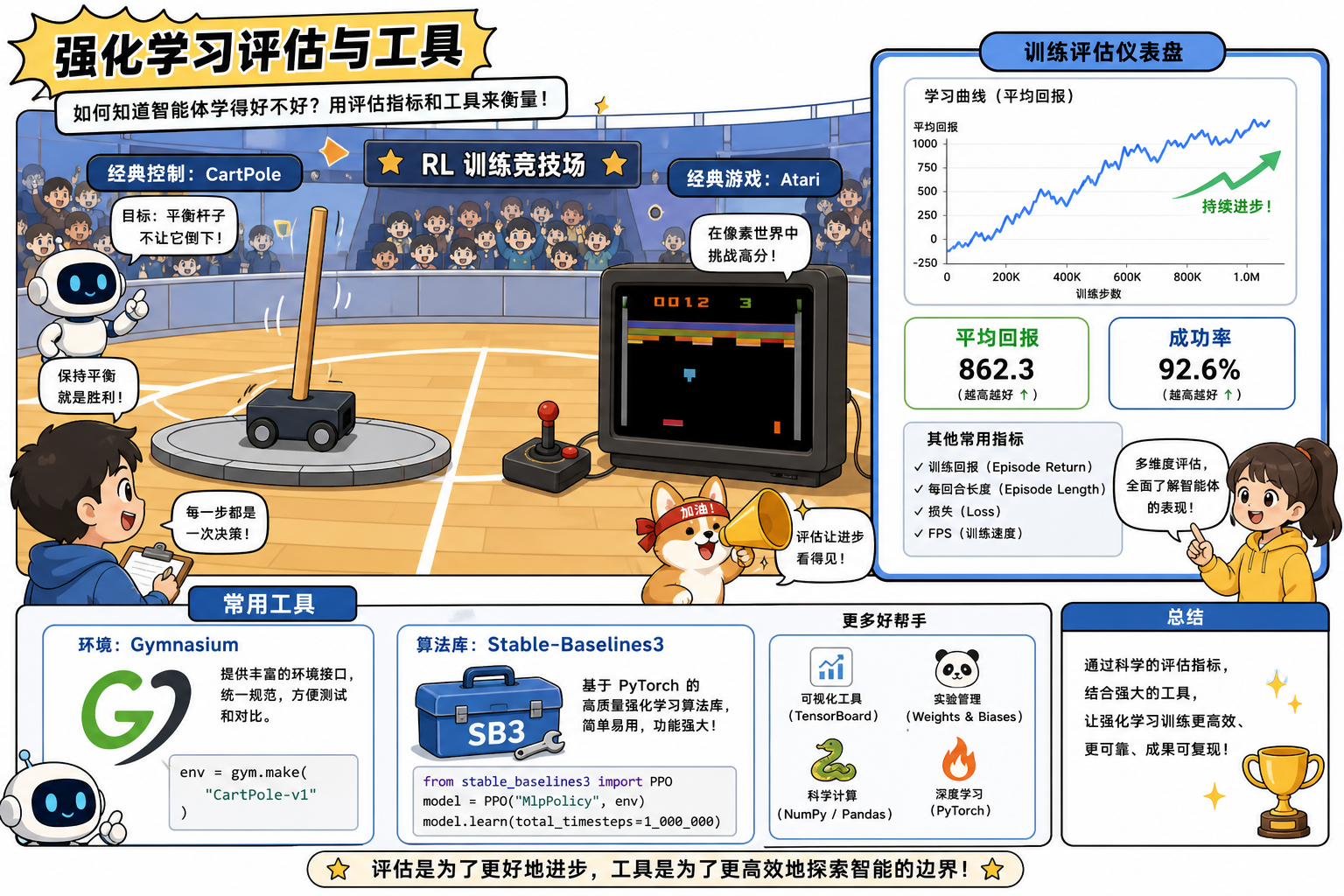
一、为什么需要标准环境
| 需求 | 标准环境的作用 |
|---|---|
| 对比算法 | 同一 MDP 上比 sample efficiency、最终回报 |
| 回归测试 | 改代码后曲线是否仍上升 |
| 教学 | CartPole 等低维任务快速验证 |
| 复现论文 | 对齐超参与环境版本 |
历史上 OpenAI Gym 是事实标准;维护现由 Gymnasium(Farama Foundation)承接,API 略有调整但心智模型一致。
段末注释:Gymnasium 为开源 RL 环境接口库,承接原 OpenAI Gym 生态;后文环境示例均指 Gymnasium API。
二、Gymnasium 核心 API
1 | import gymnasium as gym |
| 成员 | 含义 |
|---|---|
observation_space |
观测空间(Box / Discrete / Dict) |
action_space |
动作空间 |
reset(seed=) |
重置,返回初始 obs |
step(a) |
返回五元组(见下) |
render() |
可视化(可选) |
step 返回值:
| 字段 | 说明 |
|---|---|
obs |
下一观测 |
reward |
即时奖励 |
terminated |
任务自然结束(失败/成功) |
truncated |
时间步上限等人为截断 |
info |
调试信息 |
Wrapper:RecordEpisodeStatistics、NormalizeObservation、FrameStack 等,见二级篇 RL-06-01-Gymnasium与环境接口.md。
三、经典基准环境
| 环境 | 难度 | 状态/动作 | 用途 |
|---|---|---|---|
| CartPole-v1 | 入门 | 4 维 Box / 离散 2 | 首跑通 DQN/PPO |
| MountainCar-v0 | 低 | 连续 / 离散 3 | 稀疏奖励、探索 |
| LunarLander-v2 | 中 | 8 维 / 离散 4 或连续 | 控制入门 |
| Atari(ALE) | 中高 | 图像 / 离散 | DQN 论文基准 |
| MuJoCo(Ant、HalfCheetah 等) | 高 | 连续 | SAC、TD3、PPO |
| Procgen / Minigrid | 中 | 图像/网格 | 泛化研究 |
选型建议:
- 零基础:CartPole → LunarLander
- 离散深度 RL:Pong / Breakout(Atari)
- 连续控制:HalfCheetah-v4、Walker2d-v4
四、评估指标
| 指标 | 定义 | 用途 |
|---|---|---|
| Episode Return | $\sum_t r_t$ | 最常用纵轴 |
| 成功率 | 达成目标的 episode 比例 | 目标明确任务 |
| Episode Length | 步数 | 检测是否早停/卡住 |
| Sample Efficiency | 达到阈值回报所需步数 | 算法对比 |
| 渐近性能 | 训练后期平均回报 | 上限对比 |
报告方式:
- 多条 seed 的 均值 ± 标准差 曲线
- 至少 3~5 个随机种子
- 滑动窗口平滑(如 100 episode MA)
避免只报「最后一次 run 的最高分」。
五、工具链对比
| 工具 | 特点 | 适用 |
|---|---|---|
| Gymnasium | 环境标准 | 必选 |
| Stable-Baselines3 | 成熟算法实现 | 快速 baseline |
| CleanRL | 单文件 PyTorch | 读源码、教学 |
| RLlib | Ray 分布式 | 大规模 |
| TensorBoard / W&B | 日志 | 曲线与超参 |
SB3 最小示例
1 | from stable_baselines3 import PPO |
评估:evaluate_policy 或自写 deterministic rollout。
六、实验复现 Checklist
| 项 | 做法 |
|---|---|
| 随机种子 | env.reset(seed=)、torch.manual_seed、numpy |
| 版本锁定 | gymnasium==x.y、sb3==x.y 写入 requirements |
| 超参记录 | config yaml / W&B |
| Checkpoint | 定期存模型,便于断点与部署 |
| 视频 | RecordVideo wrapper 留档最佳策略 |
| 计算预算 | 注明 total_timesteps、硬件 |
七、向量化与加速
| 方式 | 说明 |
|---|---|
SyncVectorEnv |
多环境并行 step,提高采样吞吐 |
| GPU | 网络前向/反向在 GPU;环境多在 CPU |
| 仿真 | Isaac Gym、MuJoCo MJX 等进一步加速 |
八、本模块二级文档(已发布)
| 文档 | 内容 |
|---|---|
| RL-06-01-Gymnasium与环境接口 | Space、Wrapper |
| RL-06-02-经典基准环境 | CartPole / Atari / MuJoCo |
| RL-06-03-评估指标 | return、样本效率 |
| RL-06-04-Stable-Baselines3与生态 | SB3、CleanRL |
| RL-06-05-实验记录与复现 | seed、config、复现 |
九、阅读顺序
- 实现:RL-04.实现框架与实践
- 应用:RL-07.应用实战
- 系列索引:RL-00.系列概述
十、小结
- Gymnasium 统一
reset/step;terminated vs truncated 要区分。 - 评估看 回报曲线 + 多 seed + sample efficiency。
- SB3 跑 baseline,CleanRL 学实现,日志与版本锁定保证可复现。