WDL 是 Workflow Description Language的缩写,有时也写作 Workflow Definition Language,是美国 Broad Institute 推出的工作流描述语言。从开发者及开发者赋予的名字中,我们就能看出WDL是一个面向生物信息/基因组学领域的专业的工具。
经过几年的发展,WDL 已经是生信行业广泛接受的一种工作流标准,具有下面的优势:
- Human-readable WDL 作为一种为工作流领域定制的语言,和 Shell、Python 等通用的脚本语言相比,没有过多复杂的概念,对使用者的计算机技能要求不高,对于生信用户容易上手。
- Portable Workflow WDL 可以在多个平台执行,比如本地服务器、SGE 集群,云计算平台等,可以做到一次编写多处执行。
- Standard 作为GA4GH支持的工作流描述语言之一,已经得到了众多大厂和行业协会的支持,形成了比较完善的生态。
WDL架构结构组件
WDL是一种流程编写语言,没有太多复杂的逻辑和语法,入门简单。首先看一个hello world的例子
1 | workflow myWorkflow { |
对于一个WDL脚本而言,有以下5个重要的核心结构
- workflow:工作流定义
- task:工作流包含的任务定义
- call:调用或触发工作流里面的 task 执行
- output:task 或 workflow 的输出定义
- runtime:task 的运行环境定义
三个顶级组件 workflow, call and task
在顶层,我们定义了一个 workflow ,我们在其中调用一组任务。任务实际上是在工作流定义块之外定义的 task ,而 call 语句则放在工作流定义块内部。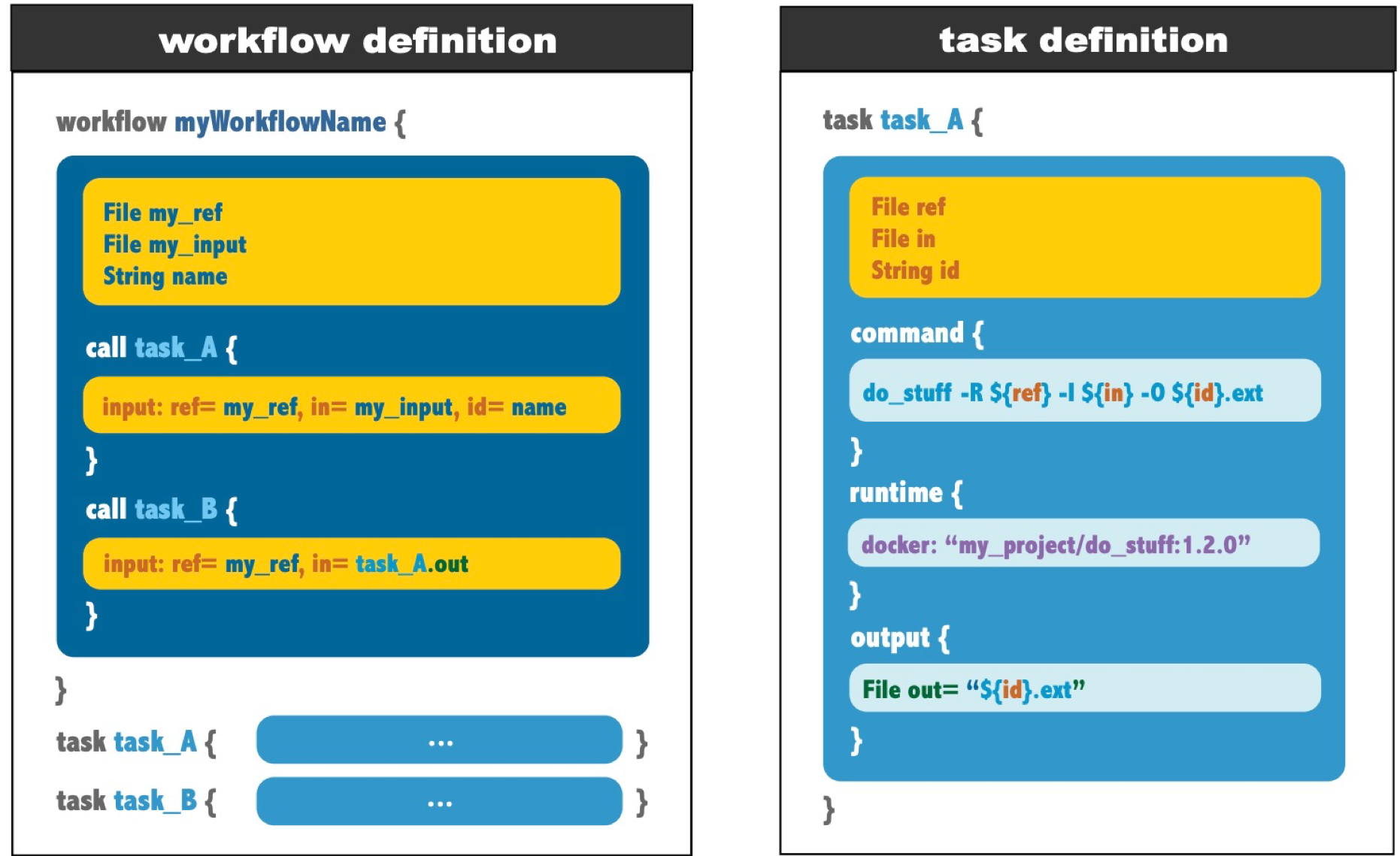
工作流块和任务定义在脚本中的排列顺序无关紧要。调用语句的顺序也无关紧要。
call
call 组件在工作流定义中用于指定应执行特定任务。在最简单的形式中,调用只需要一个任务名称。 或者,我们可以添加一个代码块来指定任务的输入变量。我们还可以修改 call 语句以别名调用任务,这允许在同一工作流中使用不同的参数多次运行相同的任务。这使得重用代码变得非常容易。当然这也提到了另一个点,通过 call 可以帮助我们将参数从workflow传到task中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 in it's simplest form
call my_task { }
with input variables
call my_task {
input:
task_var1 = workflow_var1,
task_var2 = workflow_var2,
...
}
with an alias and input variables
call my_task as task_alias {
input:
task_var1 = workflow_var1,
task_var2 = workflow_var2,
...
}
同时通过使用 call 我们可以在不同的任务之间实现输入输出的衔接和调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14workflow myWorkflow {
# 调用一个taskA 并在其中定义了task的输出结果 output
call taskA{
****
}
call taskB{
input: # 声明task copy_file的输入参数
input_file = taskA.output
}
output {
# 保存 copy_file的结果文件 output_file
File output_file = copy_file.output_file
}
}
task
task 可以理解成其他语言中的 模块/包,是一个可以完成特定工作的任务单元,一个完整的 task 中会声明执行task所需要的所有信息包括输入文件和需要指定的输入参数(input),执行的具体命令(command),以及执行后会得到的结果文件(output)。除此之外还可以通过 runtime、meta 和 parameter_meta 组件提供其他(可选)执行命令所需要的属性信息,比如环境和硬件资源(runtime)。一个 task 中常见的组件如下:
- task 代表任务,读取输入文件,执行相应命令,然后输出;
- input 指定task运行时需要提供的输入参数和数据类型,无默认值的在调用task时,需要在call过程中指定。
- parameter_meta 可选参数,通过键值对的形式提供每个输入参数的说明
- command 对应的就是执行的命令,比如一条具体的gatk的命令;
- output 指定task的输出值。下游其他task需要调用的结果需要明文输出
- runtime task在计算节点上的运行参数,包括 CPU、内存、docker 镜像等
- Metadata 记录需要记录到task中的一些元数据信息,比如作者信息。
一个简单的示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42 最简单的例子
task my_task {
input { ...
}
command <<< ...
>>
output { ...
}
}
一个相对复杂的示例
task demo{
# 说明执行task所需的输入文件
input {
String memory_mb = 1G
File input_file
}
# 进行一些变量的处理和定义
output_file = "output.txt"
# 提供每个参数的说明
parameter_meta {
memory_mb: "Amount of memory to allocate to the JVM"
input_file: "The Filename of the sample in demo task"
}
# 定义声明具体需要执行的命令
command <<<
cp ~{input_file} ~{output_file}
>>>
# 声明任务执行所需要的相关资源配置
runtime {
docker: "ubuntu:latest"
}
# 任务的元信息说明
meta {
author: "Joe Somebody"
email: "joe@company.org"
}
# 任务执行后需要输出的的结果文件
output { #说明输出
File output_file=output_file
}
}
task的执行顺序和调用的顺序、书写顺序无关,但撰写过程应该尽可能保持整个流程的可读性。
可以将task理解为编程语言中的函数,每个函数读取输入的参数,执行代码,然后返回,command对应执行的具体代码,output对应返回值。在wdl中,DAG关系就是由input 和 output来构建确认的。
workflow
workflow 组件是 WDL 脚本所需的顶级组件。它包含调用task组件的调用语句,以及工作流级输入定义。
每个wdl脚本都必须有且仅有一个 workflow ,在其中定义了整个流程的输入数据(input)和输出数据(output)。并通过 call 完成相应 task 任务的调用。
在执行阶段,wdl解析程序,会根据每个任务的输入和输出构建整个流程的有向无环图并依次进行任务的处理和分析。同时一个wdl文件中定义的 workflow 可以被其他 wdl 文件引用,从而实现 workflow 的复用。
1 | 声明workflow |
如果我们调用了多个不同的task任务,wdl在解析过程中会根据任务的输入输出文件进行拓扑排序,对独立的任务进行并行处理
其他核心组件
input & output
在前面的示例中,我们多次看到input和output的声明,不难发现,其实所有输入输出的定义前面都有一个关键字 File或String,这两个是wdl中最基本的变量类型关键字,因为我们在定义一个新的变量时,都需要对变量的类型进行声明,wdl原生支持的类型如下:
| 关键字 | 说明 |
| ———- | ————————————————————- |
| String | 字符串 |
| Int | 整数 |
| Float | 浮点数 |
| File | 文件(会校验文件是否存在) |
| Boolean | 布尔型 |
| Array[T] | 属组(数组的内部也需要指定,例如Array[File] 或 Array[String] |
| Map[K, V] | 相当于字典 |
| Pair[X, Y] | 含有两个关键字的特殊属组 |
| Object | 对象,比如解析json文件时 |
关于每一种变量的使用,以及 WDL 的更多使用技巧,请参考官方规范文档。
再就是我们在 task层的变量可以引用workflow层的变量,也可以直接传参。下面我举个例子来说明一下:
1 | workflow helloHaplotypeCaller { |
在workflow层,我们定义了两个变量,Ref和Sample,在call demoA 的过程中,我们用input语句将它们传给了task层的 RefFasta 和 sampleName ,这样的话,提升了传参的复用——只用给Ref和Sample两个变量传参,多个task都可以引用它们。而其它的变量 GATK 则可以由输入文件一起传入。
批量计算 runtime
用于配置任务运行时的相关参数。
使用批量计算作为后端时,主要的 runtime 参数有:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28cluster:
计算集群环境
支持serverless 模式和固定集群模式
mounts:
挂载设置
支持 OSS 和 NAS
docker:
容器镜像地址
支持容器镜像服务
simg:
容器镜像文件
支持singularity 镜像
systemDisk:
系统盘设置
包括磁盘类型和磁盘大小
dataDisk:
数据盘设置
包括磁盘类型、磁盘大小和挂载点
memory:
所需的任务内存
cpu:
所需的计算核心数目
timeout:
作业超时时间
maxRetries:
指令允许定义在发生故障时可以重新提交流程实例的最大次数。
continueOnReturnCode: [0,1]
指定判定任务成功的返回码,默认是0成功,非0是任务失败。
具体的参数解释及填写方法,请参考 Cromwell 官方文档
除此之外,还有一些其他的概念
- command
- parameter_meta
- meta
从官方版本45开始,Cromwell 使用批量计算作为后端,支持 glob 和 Call caching 两个高级特性。
参考文档
在学习编写 WDL 的过程中,可以参考 Broad 官方的一些 GATK工作流 借鉴和学习 WDL 的用法。