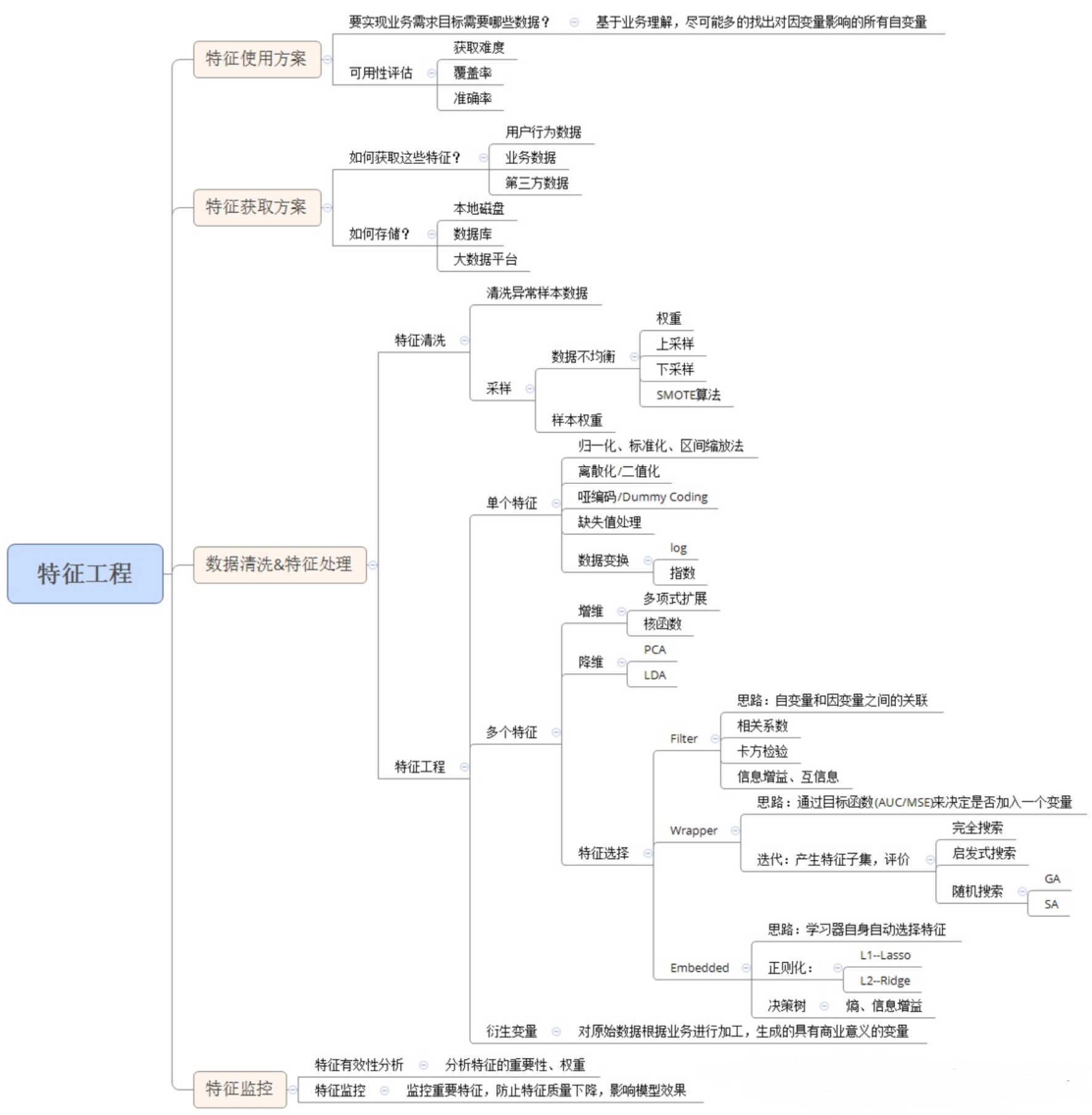
对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。由此可见,数据和特征在模型的整个开发过程中是比较重要。特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,以设计更高效的特征以刻画求解的问题与预测模型之间的关系。
虽然说理论上只要我们能掌握一类事件的全部特征,并理解特征在整个事件种发挥的作用,我们就可以预测一件事情发生的过程细节,并精准的获取事件的走向和结果。但是显然这会带来巨大的计算成本,让我们对于一些无足轻重的事情花费巨大的代价(比如预测一个某个患者的生存周期,我们不可能去考虑他出交通事故的可能性,更不可能考虑第三次世界大战的发生导致死亡);当然除了更多的计算成本外,随着特征的增加,我们必须也要补充对应的训练样本,来捕获所有的特征数据及每个特征的作用(权重。所以在实际的模型应用中并不是特征越多越好,特征越多固然会给我们带来很多额外的信息,但是与此同时,一方面,这些额外的信息也增加实验的时间复杂度和最终模型的复杂度,造成的后果就是特征的“维度灾难”,使得计算耗时大幅度增加;另一方面,可能会导致模型的复杂程度上升而使得模型变得不通用。所以我们就要在众多的特征中选择尽可能相关的特征和有效的特征,使得计算的时间复杂度大幅度减少来简化模型,并且保证最终模型的有效性不被减弱或者减弱很少。因此在进行下游的机器学习、深度学习等模型训练签,我们需要对数据特征进行一些提前的处理工作,这些工作涵盖了多个细分领域
- 数据编码:对于分类变量,我们使用不同的数字标签([-1,1]),或者向量(红[1,0,0]; 黄[0,1,0] 绿[0,0,1])等进行转码。
- 数据预处理:比如数据的归一化、标准化或者缩放处理;以及缺失值的处理
- 特征选择:筛选有效的特征用于下游模型的训练。单变量选择、多变量选择等。
- 特征降维:进行多为特征的整合,来降低训练模型接收的维度。