决策树(decision tree)是一种基本的分类与回归方法。依托于策略抉择而建立起来的树。机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。 树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,从根节点到叶节点所经历的路径对应一个判定测试序列。决策树可以是二叉树或非二叉树,也可以把他看作是 if-else 规则的集合,也可以认为是在特征空间上的条件概率分布。决策树在机器学习模型领域的特殊之处,在于其信息表示的清晰度。决策树通过训练获得的 “知识”,直接形成层次结构。这种结构以这样的方式保存和展示知识,即使是非专家也可以很容易地理解。
- 决策树的优点:
- 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解,
- 决策树模型可以可视化,非常直观
- 应用范围广,可用于分类和回归,而且非常容易做多类别的分类
- 能够处理数值型和连续的样本特征
- 决策树的缺点:
- 很容易在训练数据中生成复杂的树结构,造成过拟合(overfitting)。剪枝可以缓解过拟合的负作用,常用方法是限制树的高度、叶子节点中的最少样本数量。
- 学习一棵最优的决策树被认为是NP-Complete问题。实际中的决策树是基于启发式的贪心算法建立的,这种算法不能保证建立全局最优的决策树(Random Forest 引入随机能缓解这个问题)。
决策树,其实算是在所有学习模型里面比较符合人类思考理解事件的过程,就是我们根据特征值进行一系列判断决策的过程,每个节点对应一次独立的决策,每次决策往往也只考虑单一的特征,随着特征的增加,整个决策过程枝繁叶茂起来,最终形成一棵决策树。在根节点,我们收集到一次实践的所有特征,然后不断在决策路径上取出某一个特征并进行判断。
举个例子: 现在有人给你介绍对象,你打听到对方的特点:白不白,富不富,美不美,然后决定去不去相亲。根据以往经验,我们给出所有可能性: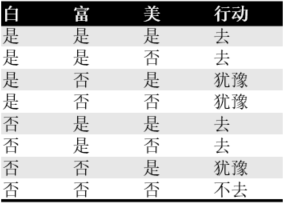
所以每当出现一个新的对象时,我们就要一个个特点去判断,于是这种判断的过程就可以画成一棵树,例如根据特点依次判断: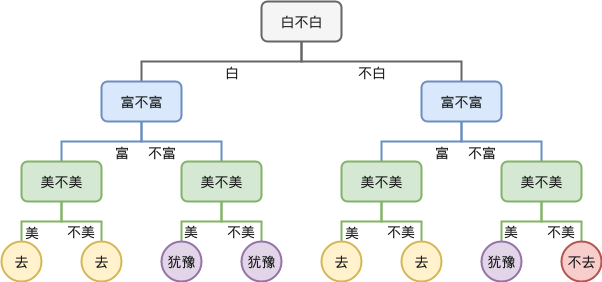
这就是决策树,每一层我们都提出一个问题,根据问题的回答来走向不同的子树,最终到达叶子节点时,做出决策(去还是不去)。可以看到,决策树没有任何特别的地方。其本质就是根据数据的某个维度进行切分,并不断重复这个过程,直至到达叶子节点(做出决策)。当然,如果切分的顺序不同,会得到不同的树。如果我们树足够大,那么所有的数据都可以实现进行精确的区分,但是这可能会直接导致泛化能力变差,模型过拟合。所以决策树的训练过程就是一个剪枝的过程。就是筛选重要特征,优先根据这些重要特征进行决策识别来提高处理效率,然后通过一定成都的剪枝提升模型的泛化能力。
上述例子中,如果仔细观察,我们发现决策树中有一些叶子节点是可以合并的,合并之后,到达某个节点时就不需要进行额外的决策,例如切分顺序“白,富,美”得到的决策树合并后如下: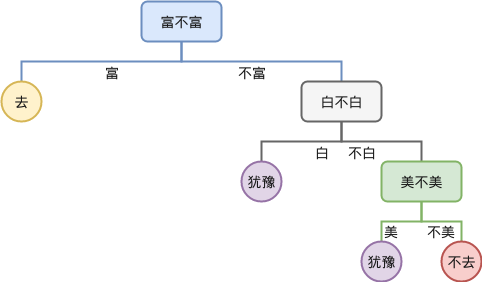
模型变得更简洁明了,同时我们也可以更容易发现那些特征发挥着更重要的作用。
举个通俗易懂的例子,如下图所示的流程图就是一个决策树,长方形代表判断模块(decision block),椭圆形成代表终止模块。
https://www.cnblogs.com/JetpropelledSnake/p/14513544.html