概念定义

强化学习(Reinforcement learning ,RL)是机器学习的三驾马车之一。讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的状态(state) 对 动作(action) 的 反应(reward), 来指导更好的动作,从而获得最大的 收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习。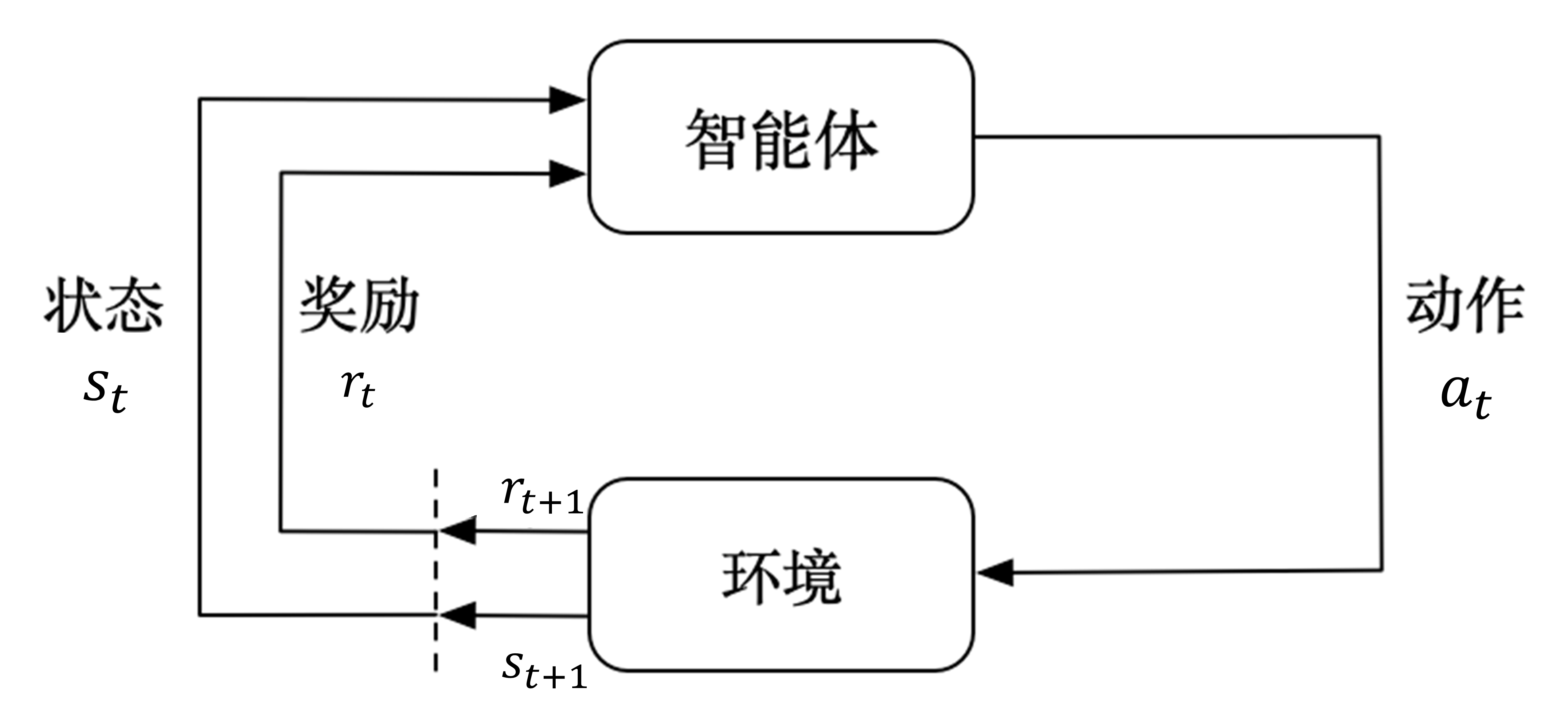
强化学习主要有以下几个特点:
- 试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
强化学习基本元素
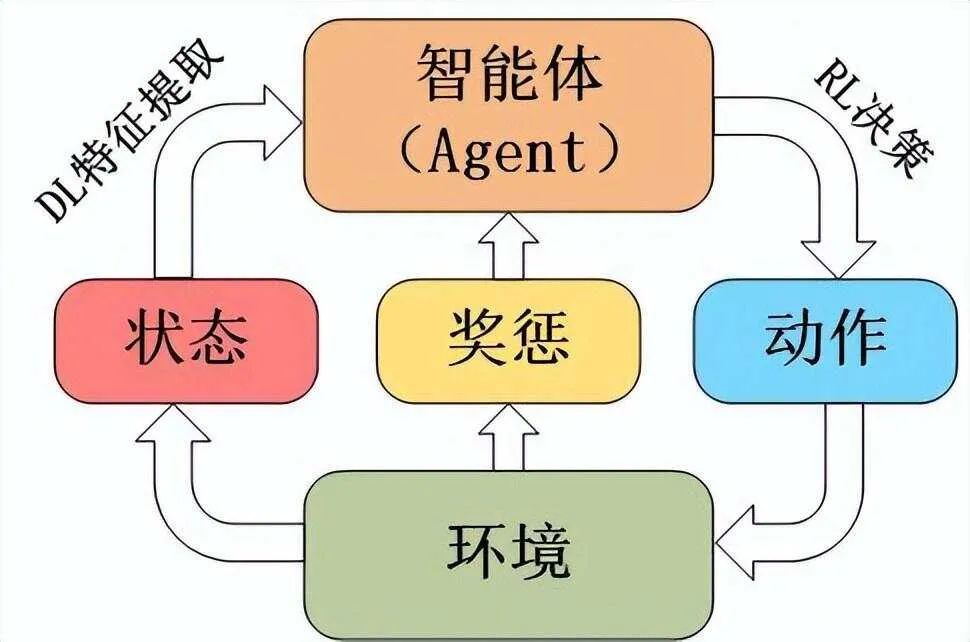
- 环境(Environment) 是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态做出一定的行动。
- 智能体(Agent) 是一个嵌入到环境中的系统,能够通过采取行动来改变环境的状态。
- 状态(State)/观察值(Observation):状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。
- 动作(Action):不同的环境允许不同种类的动作,在给定的环境中,有效动作的集合经常被称为动作空间(action space),包括离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces),例如,走迷宫机器人如果只有东南西北这 4 种移动方式,则其为离散动作空间;如果机器人向 360◦ 中的任意角度都可以移动,则为连续动作空间。
- 奖励(Reward):是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了智能体在某一步采 取了某个策略的表现如何。
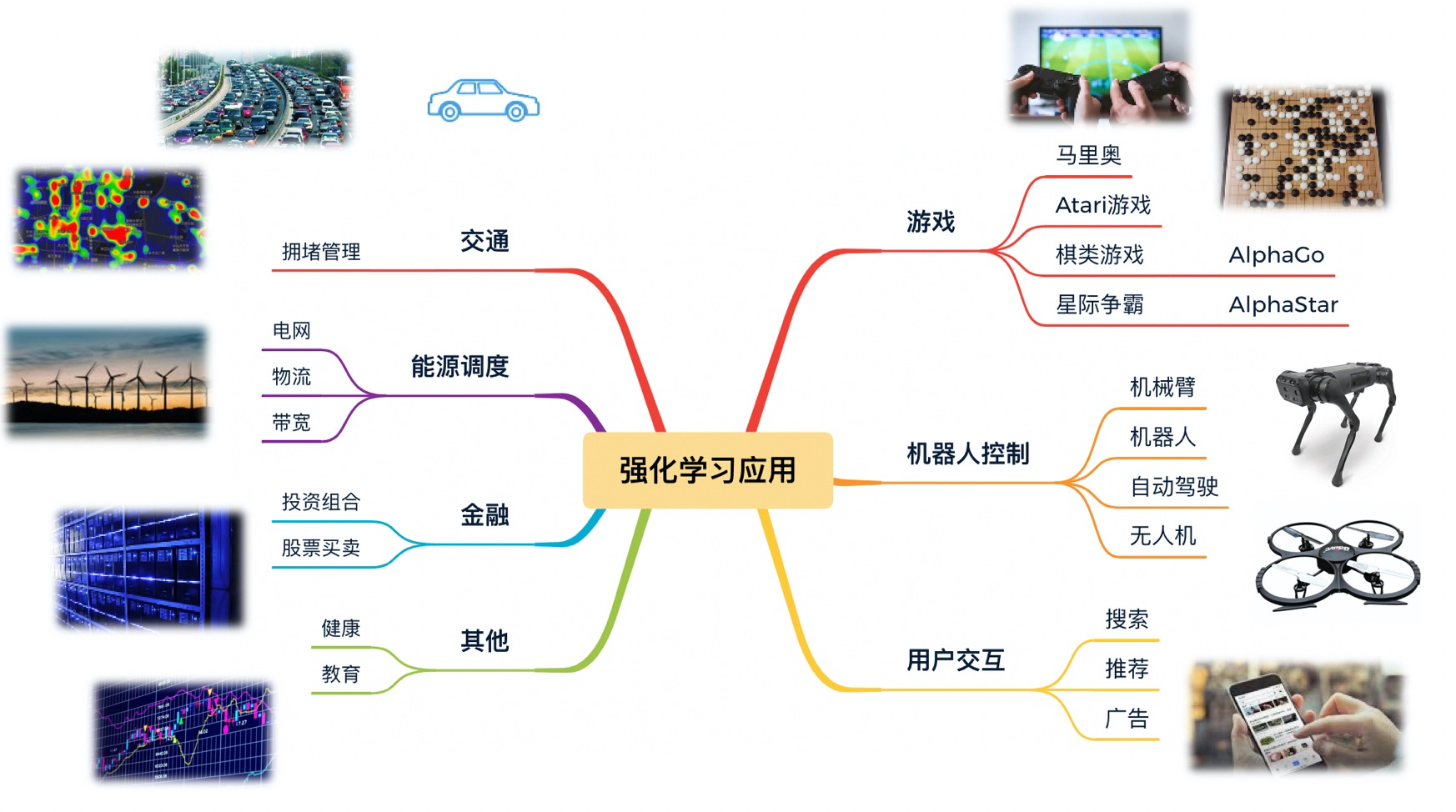
应用场景
术语
策略(Policy)
策略是智能体用于决定下一步执行什么行动的规则。
- 可以是确定性的,一般表示为:$\mu$:$\alpha_t=\mu(\alpha_t|s_t)$,其中$\mu(\alpha_t|s_t)$表示在状态s_t下,策略$\mu$所选择的动作是$\alpha_t$的概率。
- 也可以是随机的,一般表示为 $\mu$:$\alpha_t~\pi(\cdot|s_t)$:
状态转移(State Transition)
状态转移,可以是确定的也可以是随机的,一般认为是随机的,其随机性来源于环境。可以用状态密度函数来表示:
$p(s’|s,a)=P(S’=s’|S=s, A=a)$
环境可能会变化,在当前环境和行动下,衡量系统状态向某一个状态转移的概率是多少,注意环境的变化通常是未知的。
回报(Return)
回报又称cumulated future reward,一般表示为 $U$,定义为$U_t=\sum_{k=0}^{\infty}R_{t+k}$ 其中, $R_{t+k}$表示第t+k时刻的奖励。agent的目标就是让Return最大化。
未来的奖励不如现在等值的奖励那么好(比如一年后给100块不如现在就给),所以$R_t+1$的权重应该小于$R_t$。因此,强化学习通常用discounted return(折扣回报,又称cumulative discounted future reward),取$\lambda$为discount rate(折扣率),$\lambda \in (0,1] $,则有,$U_t=\sum_{k=0}^{\infty}\lambda^kR_{t+k}$
价值函数(Value Function)
举例来说,在象棋游戏中,定义赢得游戏得1分,其他动作得0分,状态是棋盘上棋子的位置。仅从1分和0分这两个数值并不能知道智能体在游戏过程中到底下得怎么样,而通过价值函数则可以获得更多洞察。
价值函数使用期望对未来的收益进行预测,一方面不必等待未来的收益实际发生就可以获知当前状态的好坏,另一方面通过期望汇总了未来各种可能的收益情况。使用价值函数可以很方便地评价不同策略的好坏。
- 状态价值函数(State-value Function):用来度量给定策略$\pi$的情况下,当前状态$s_t$的好坏程度。
- 动作价值函数(Action-value Function):用来度量给定状态$s_t$和给定策略$\pi$下,执行动作$a_t$的好坏程度。
算法
算法分类
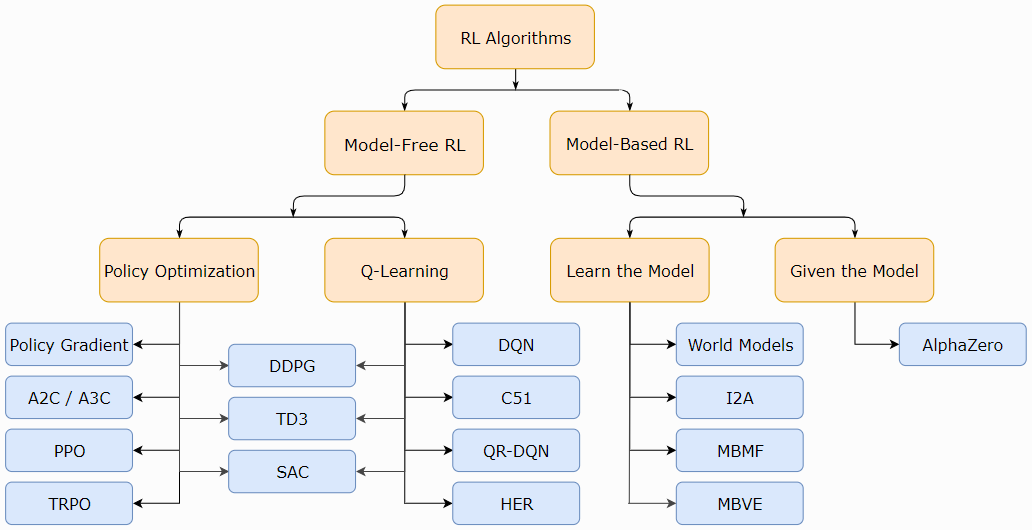
按照环境是否已知划分:免模型学习(Model-Free) vs 有模型学习(Model-Based)
- Model-free 就是不去学习和理解环境,环境给出什么信息就是什么信息,常见的方法有policy optimization和Q-learning。
- Model-Based 是去学习和理解环境,学会用一个模型来模拟环境,通过模拟的环境来得到反馈。Model-Based相当于比Model-Free多了模拟环境这个环节,通过模拟环境预判接下来会发生的所有情况,然后选择最佳的情况。
一般情况下,环境都是不可知的,所以这里主要研究无模型问题。
按照学习方式划分:在线策略(On-Policy) vs 离线策略(Off-Policy)
- On-Policy 是指agent必须本人在场, 并且一定是本人边玩边学习。典型的算法为Sarsa。
- Off-Policy 是指agent可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则, 离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习,也没有必要是边玩边学习,玩和学习的时间可以不同步。典型的方法是Q-learning,以及Deep-Q-Network。
按照学习目标划分:基于策略(Policy-Based)和基于价值(Value-Based)。
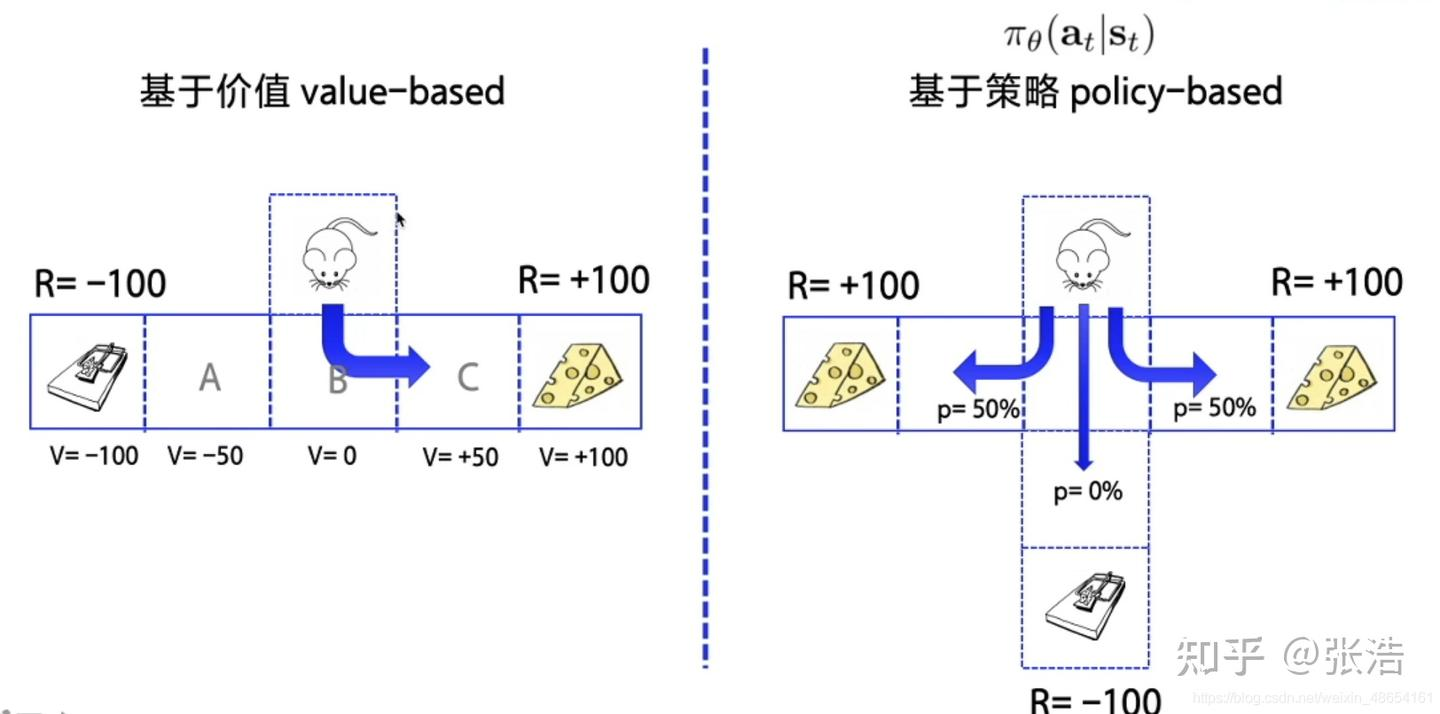
- Policy-Based 的方法直接输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体进行考虑。适用于非连续和连续的动作。常见的方法有Policy gradients。
- Value-Based 的方法输出的是动作的价值,选择价值最高的动作。适用于非连续的动作。常见的方法有Q-learning、Deep Q Network和Sarsa。
更为厉害的方法是二者的结合:Actor-Critic,Actor根据概率做出动作,Critic根据动作给出价值,从而加速学习过程,常见的有A2C,A3C,DDPG等。
经典算法
经典算法:Q-learning,Sarsa,DQN,Policy Gradient,A3C,DDPG,PPO
下面我们挑选一些有代表性的算法进行讲解:
- 基于表格、没有神经网络参与的Q-Learning算法
- 基于价值(Value-Based)的Deep Q Network(DQN)算法
- 基于策略(Policy-Based)的Policy Gradient(PG)算法
- 结合了Value-Based和Policy-Based的Actor Critic算法。
reference
OpenAI: Kinds of RL Algorithms
强化学习入门:基本思想和经典算法
详解经典强化学习算法,搞定“阿尔法狗”下围棋