前文介绍了多层感知机,而多层感知机,其实是神经网络的一种特殊情况(只有一层隐藏层 & 全链接),而当我们引入多层隐藏层进行分析时,就是常说的深度学习,其中的深度,就是指的有多个隐藏层。
整体框架结构上,深度学习和多层感知机并没有基础结构件的区别,但是就像我们代码为了提高代码的复用率一样,当我们具有非常多隐藏层的时候,我们往往需要定义一个抽象的层以及定义一个抽象的块,来帮助我们更好的对模型结构进行复用。
层和块
介绍神经网络时,我们
- 开始我们关注的是具有单一输出的线性模型。,整个模型只有一个输出。 单个神经网络 (1)接受一些输入; (2)生成相应的标量输出; (3)具有一组相关 参数(parameters),更新这些参数可以优化某目标函数。
- 然后,考虑具有多个输出的网络时, 我们利用矢量化算法来描述整层神经元。 像单个神经元一样,层(1)接受一组输入, (2)生成相应的输出, (3)由一组可调整参数描述。 当我们使用softmax回归时,一个单层本身就是模型。 然而,即使我们随后引入了多层感知机,我们仍然可以认为该模型保留了上面所说的基本架构。
- 对于多层感知机而言,整个模型及其组成层都是这种架构。 整个模型接受原始输入(特征),生成输出(预测), 并包含一些参数(所有组成层的参数集合)。 同样,每个单独的层接收输入(由前一层提供), 生成输出(到下一层的输入),并且具有一组可调参数, 这些参数根据从下一层反向传播的信号进行更新。
我们可以看到,整体模式其实都是 根据一些参数, 获取原始输入,得到一个输出结果。
而一些项目我们可能会用到非常多的层, 例如,在计算机视觉中广泛流行的ResNet-152架构就有数百层, 这些层是由层组(groups of layers)的重复模式组成。 这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉比赛 的识别和检测任务 (He et al., 2016)。 目前ResNet架构仍然是许多视觉任务的首选架构。 在其他的领域,如自然语言处理和语音, 层组以各种重复模式排列的类似架构现在也是普遍存在。
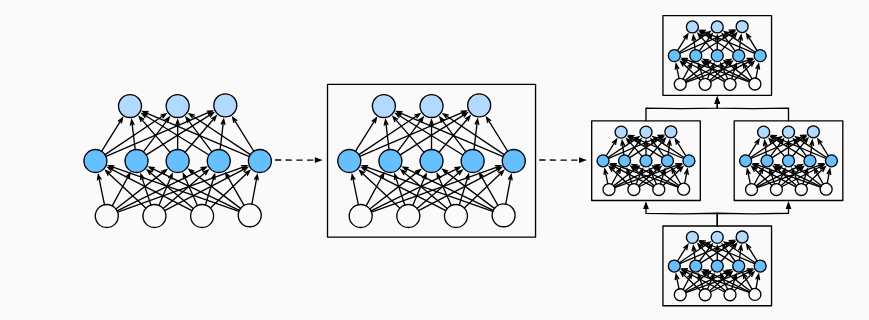
为了实现这些复杂的网络,我们引入了神经网络块的概念。 块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的,如下所示。 通过定义代码来按需生成任意复杂度的块, 我们可以通过简洁的代码实现复杂的神经网络。