当你从 **蛋白质结构数据库(Protein Data Bank,PDB)**下载条目、或使用 AlphaFold 等管线导出结构时,文件名常为 .cif 或 .mmcif。这类文本本质上是 **晶体学信息文件(Crystallographic Information File,CIF)**家族的一员;描述蛋白质/核酸/配体复合物时常采用 宏分子 CIF(macromolecular CIF,mmCIF),在 wwPDB 生态里也常被称为 PDBx/mmCIF。它比老式固定宽度 PDB 文本更易扩展:字段名自描述、表格行数不受列宽限制,适合多链、翻译后修饰、配体化学与大规模组装体。
段末注释:wwPDB 为全球 PDB 档案库的协作组织;mmCIF 基于 STAR 语法(键–值 +
loop_表格);后文沿用 mmCIF、CIF,必要时区分「小分子晶体 CIF」与「宏分子 mmCIF」。
字段全称与校验规则以 mmcif.wwpdb.org 与 PDBx/mmCIF 词典为准。
1. 语法骨架:像「标签笔记本」一样的 STAR/mmCIF
mmCIF 建立在 STAR(Self-defining Text Archive and Retrieval) 文本格式之上,可读性规律可以记成三条:
data_名称:打开一个新数据块(data block),类似笔记本里新开一章;一个文件可有多个块,常见宏分子条目里主要用一个块承载整套结构。_类目.项目名 值:单行键–值,点号前是类目(category),点后是项目(item),对应词典里的定义与允许类型。loop_:下列若干行先列出本表有哪些列(同上形式的_类目.项目,可无值),再跟多行数据行,列顺序与声明一致——像表格表头 + 逐行记录。
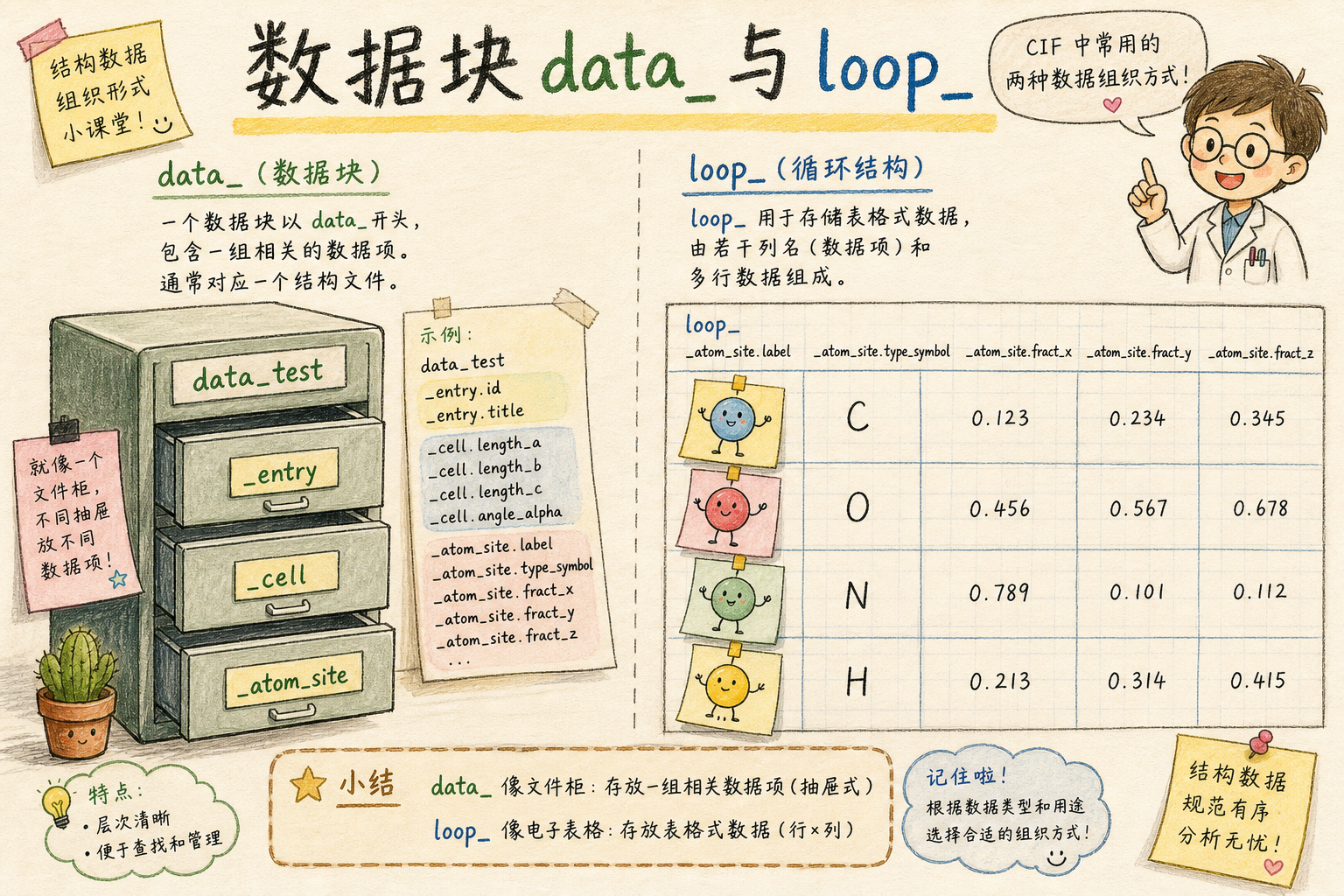
科学意义:晶体学与结构生物学需要同时存档「物理测量 metadata」「化学拓扑」「原子坐标」「衍射/冷冻电镜重构统计」等异质信息;键–值适合唯一项(如晶胞边长),loop_ 适合「每个原子一行」「每个键一行」的可变长度列表,避免 PDB 固定列被超长字段撑爆。
2. 生物学/化学语境里最先值得盯的几组类目
2.1 条目身份:_entry.id
对应 PDB ID(如 8ABC)。阅读批量下载文件时,用它做去重与数据库 API 关联。
2.2 晶胞与对称:_cell.*、_symmetry.*、_space_group_*
实验晶体结构里,原子坐标常描述在不对称单元(asymmetric unit)中,再通过空间群对称操作生成完整晶体;_cell.length_a/b/c、_cell.angle_alpha/beta/gamma 给出**晶胞(unit cell)**几何——本质上是用三个边长与三个夹角,界定周期性重复排列的「最小盒子」,离子/小分子在盒子里堆积方式即晶体化学关心的堆垛与氢键网络。
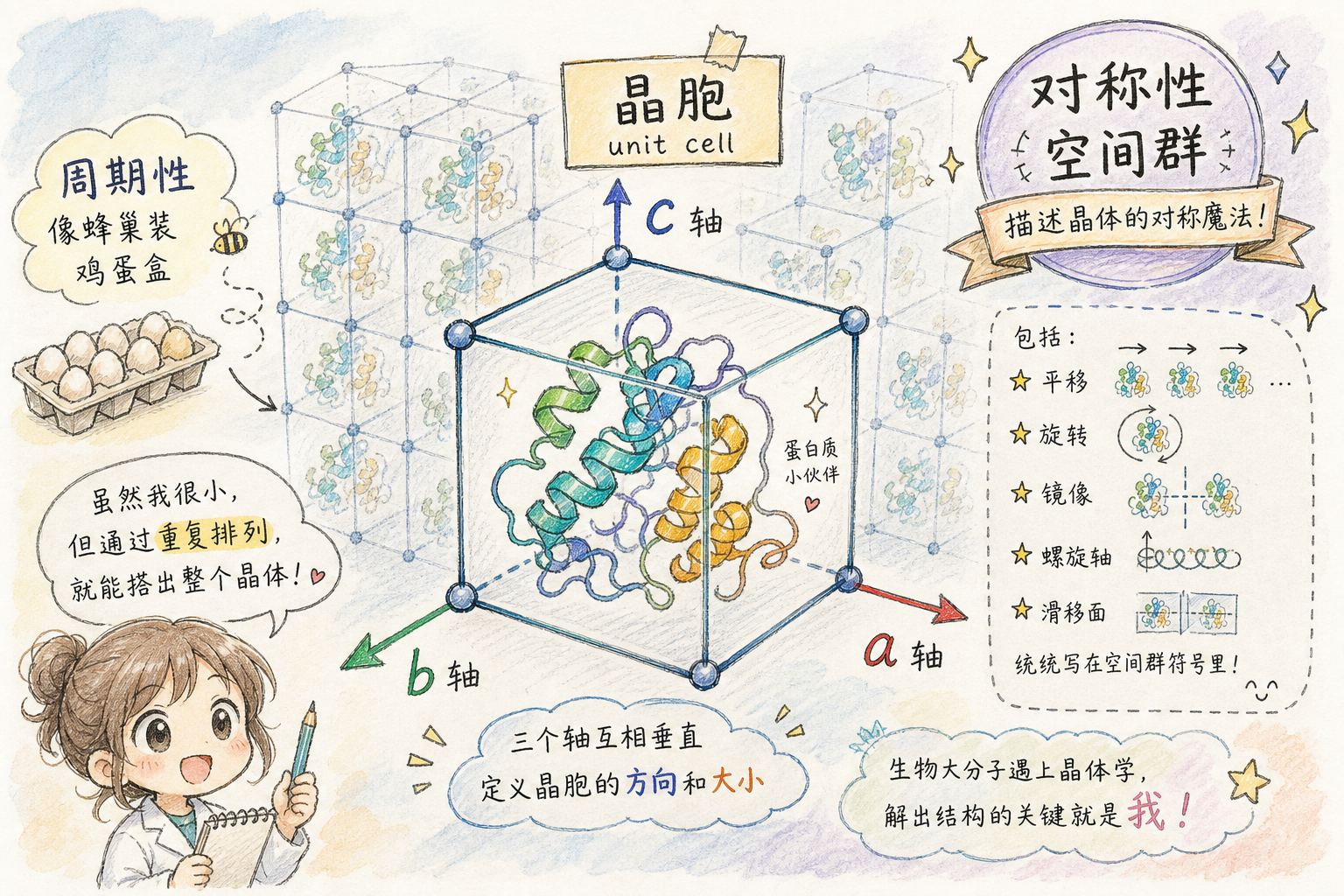
预测结构或冷冻电镜单颗粒重构条目仍可能出现晶胞字段(有时取占位或约定默认),解读时要结合 EXPDTA(实验方法)等说明:不必把「晶胞数字」一律当成真实衍射晶体的测量结果。
段末注释:**空间群(space group)**描述晶体对称操作的集合(平移、旋转、反演等的组合),决定如何从不对称单元复制出整块晶体。
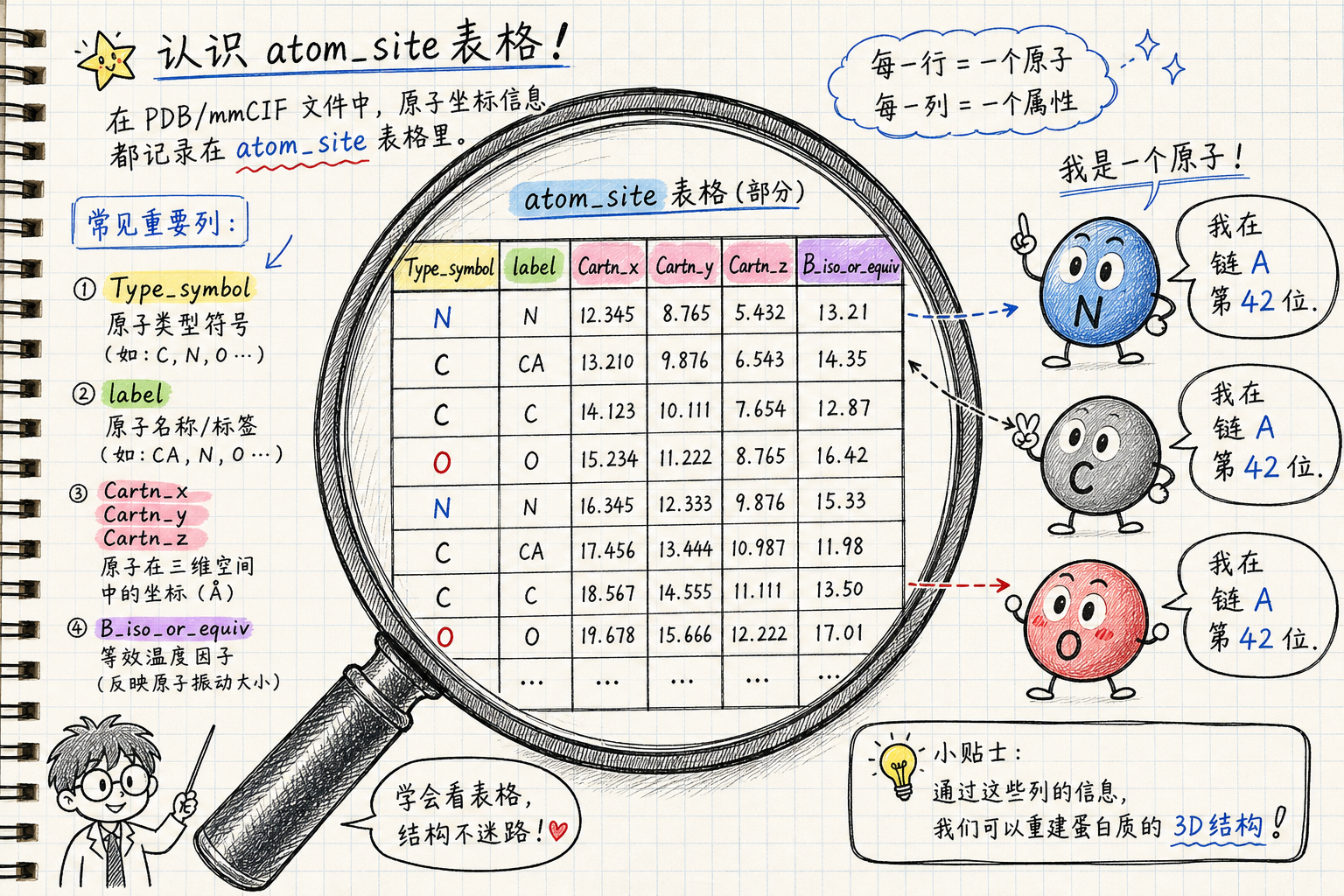
2.3 原子坐标表:loop_ _atom_site.*
这是最常用的「逐原子清单」。典型列包括(具体条目未必全列齐):
常见 _atom_site 列(示意) |
概念/科学意义 |
|---|---|
group_PDB |
ATOM(聚合物标准残基) vs HETATM(配体、离子、溶剂等) |
type_symbol |
元素符号(化学物种) |
label_atom_id / auth_atom_id |
原子名;label_* 与 auth_* 分别对应标准化标注与作者/ deposited 习惯 |
label_comp_id / auth_seq_id |
残基/组分名与序号,映射突变、修饰位点 |
label_asym_id |
链 ID;沟通序列比对与分子界面分析 |
Cartn_x/y/z |
笛卡尔坐标(Å),三维构象的直接载体 |
occupancy |
占位率:无序或多构象时可见小于 1 的值 |
B_iso_or_equiv |
各向同性 B-factor 或等效值;晶体学里反映热振动/无序;预测结构里常与置信度相关(视数据来源) |
表中 occupancy 与 B_iso_or_equiv(B-factor)在晶体学里的理化含义、与预测结构「借用 B 列存置信度」的区别,已作为知识补充写在同目录 fileformat-pdb.md 的 §2.2,并配有示意插图,可与本节对照阅读。
小分子配体/对接侧常用的 Molfile/SDF/MOL2 文本格式说明见 fileformat-molfile.md、fileformat-sdf.md、fileformat-mol2.md(与 chem_comp/对接工作流互补)。
2.4 聚合物实体与小分子:entity / entity_poly vs chem_comp
entity/entity_poly:描述「这条聚合物实体」是什么——例如蛋白质一条链的序列类型、长度、是否为 polymer。生物学叙事(结构域划分、翻译后修饰标注)常先要理清 entity 与链的对应。chem_comp:词典式列出文件中出现的化学组分(标准氨基酸三字码、辅因子、抑制剂、离子等),连接 PubChem/内部组分 ID,承载化学识别信息。
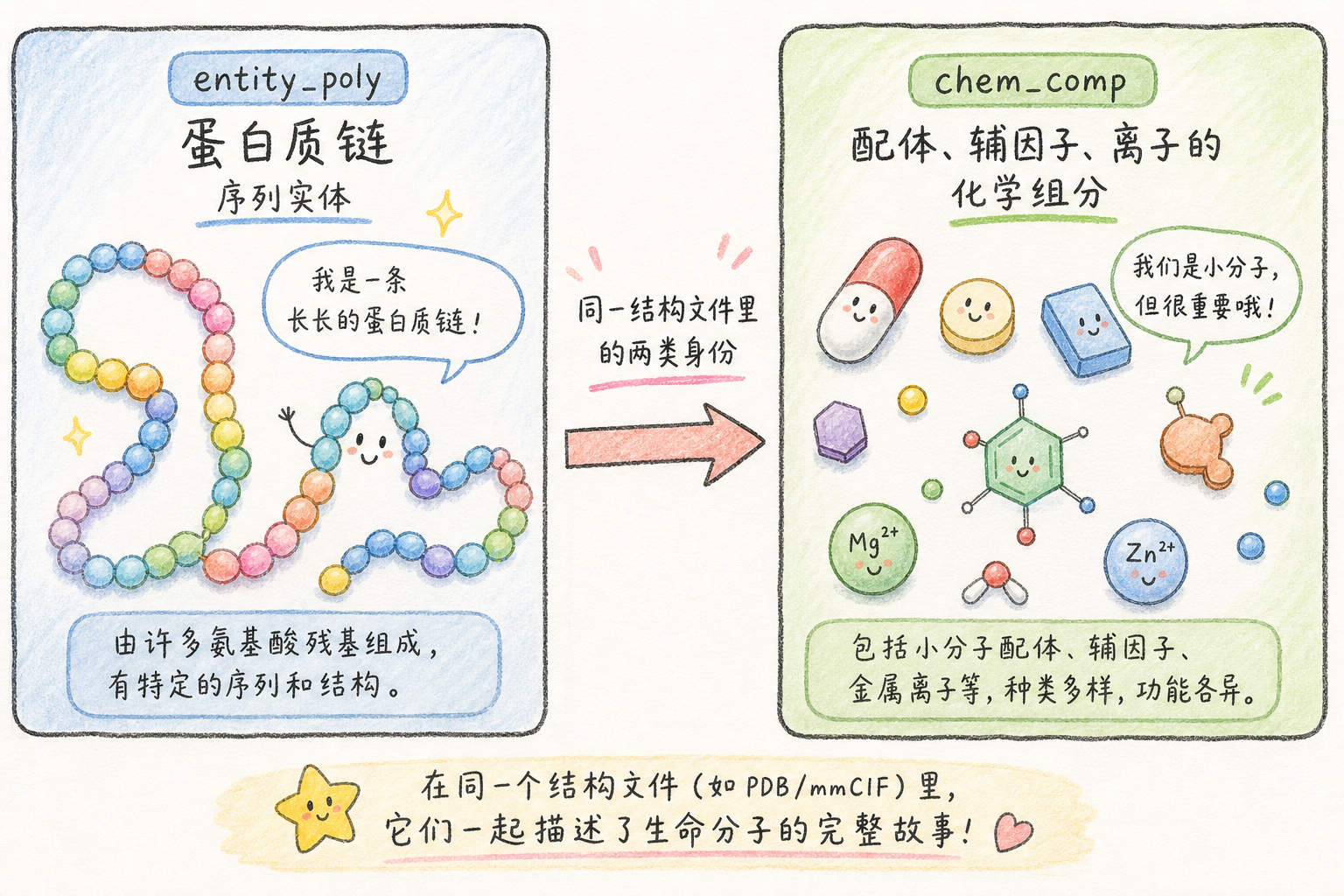
化学意义:同一晶体里既有 酶 又有 底物类似物 时,entity_poly 告诉你「哪段序列是酶」,_chem_comp / _atom_site 告诉你「配体原子如何命名与键合」;解析对接与药效团分析时,二者缺一不可。
3. 与 PDB 文本的对照(何时优先 mmCIF)
| 场景 | 更合适的格式 |
|---|---|
| 极长链、多链复合物、复杂配体 | mmCIF(字段长度与表格行数灵活) |
| 老脚本、部分可视化仅认 PDB | PDB |
| AlphaFold DB、最新 wwPDB 分发 | 常见 mmCIF 为主或双格式 |
同目录下的 PDB 说明见:fileformat-pdb.md。
4. 极简虚构示例(教学用,非真实条目)
1 | data_demo |
真实文件还包含对称、struct_asym、entity 等大量关联信息;应用层应用 gemmi、Biopython MMCIF、iotbx 等库解析,避免手写字符串切片。
5. 解析与校验工具(实践入口)
- gemmi(C++/Python):读写 mmCIF、晶胞对称、结构编辑常用。
- Biopython
MMCIF2Dict/ 结构对象:与序列、链对象衔接。 - wwPDB 校验服务:提交前检查类目完备性与化学一致性。
6. 小结 Checklist
data_定位数据块;loop_读作「表」。_cell/ 对称相关:晶体周期性几何;预测条目需结合实验类型解读。_atom_site:坐标与 B-factor/占位率;链与序列号用label_*/auth_*时注意数据库约定。entity_polyvschem_comp:分清「生物聚合物身份」与「化学组分词典」。- 需要与 PDB 对照或衔接 AlphaFold 导出时,优先确认下载的是 mmCIF 还是 PDB,再选解析栈。